
Trong kỷ nguyên số, dữ liệu được ví như “nguồn dầu mỏ” mới. Ai nắm giữ nguồn dữ liệu lớn hơn, chính xác hơn, người đó sẽ chiếm ưu thế trên thị trường. Để thu thập nguồn tài nguyên vô tận này từ Internet, các công cụ quét dữ liệu truyền thống (Crawler) từng là bá chủ. Tuy nhiên, sự bùng nổ của trí tuệ nhân tạo đã khai sinh ra một khái niệm mạnh mẽ hơn: AI Crawler.
Vậy chính xác AI crawler là gì? Công nghệ này hoạt động ra sao và tại sao nó lại làm thay đổi hoàn toàn cuộc chơi dữ liệu hiện nay? Hãy cùng tìm hiểu chi tiết qua bài viết dưới đây.
AI crawler là gì?
AI Crawler (hay Trình thu thập dữ liệu tích hợp trí tuệ nhân tạo) là một phần mềm hoặc bot tự động, sử dụng các thuật toán Học máy (Machine Learning) và Xử lý ngôn ngữ tự nhiên (NLP) để duyệt qua các trang web, đọc hiểu ngữ cảnh và thu thập dữ liệu một cách thông minh.

Khác với các công cụ web scraping thông thường vốn chỉ biết “sao chép và dán” dữ liệu thô một cách máy móc, AI Crawler có khả năng tư duy gần như một con người: chúng có thể tự hiểu bố cục trang web, tự phân loại thông tin quan trọng và loại bỏ rác dữ liệu ngay trong quá trình cào.
Ví dụ dễ hiểu: Nếu bạn muốn cào giá sản phẩm trên các sàn thương mại điện tử:
- Crawler truyền thống: Bạn phải chỉ tận tay cho nó vị trí của dòng chữ chứa giá (bằng code HTML). Nếu sàn đổi giao diện, nó sẽ bị “mù” và báo lỗi.
- AI Crawler: Nó tự “nhìn” vào trang web, nhận diện đâu là ô giá tiền (dù giao diện có thay đổi thế nào) và tự động lấy về chính xác.
Sự khác biệt cốt lõi giữa AI Crawler và Crawler truyền thống
Để hiểu tại sao công cụ cào dữ liệu AI lại là một bước nhảy vọt, hãy cùng đặt chúng lên bàn cân so sánh với công nghệ cũ:
| Tiêu chí so sánh | Crawler truyền thống | AI Crawler thế hệ mới |
| Cơ chế định vị | Dựa trên mã nguồn cố định (XPath, Regex, HTML). | Dựa trên Thị giác máy tính (Computer Vision) và NLP để hiểu bố cục. |
| Phản ứng khi web đổi giao diện | Bị lỗi (Break). Cần lập trình viên vào sửa lại code. | Tự thích nghi. Nhận diện lại phần tử mới mà không cần can thiệp thủ công. |
| Xử lý cơ chế chống cào | Dễ dàng bị chặn bởi Captcha, Cloudflare hoặc tường lửa. | Giả lập hành vi người dùng cực kỳ tinh vi để vượt qua các bộ lọc. |
| Chất lượng dữ liệu thu về | Dữ liệu thô, lộn xộn, cần rất nhiều thời gian để làm sạch (data cleaning). | Dữ liệu đã được phân loại cấu trúc, làm sạch và gắn nhãn sẵn sàng sử dụng. |
Cách thức hoạt động thông minh của AI Crawler
Một AI Crawler không hoạt động theo những dòng code định sẵn cứng nhắc. Quy trình hoạt động của nó mô phỏng lại cách con người duyệt web thông qua 3 bước cốt lõi:
Bước 1: Nhận diện trực quan
AI Crawler quét qua giao diện hiển thị của trang web giống như mắt người. Nó xác định đâu là tiêu đề, đâu là hình ảnh sản phẩm, đâu là phần bình luận mà không phụ thuộc hoàn toàn vào cấu trúc thẻ HTML bên dưới.
Bước 2: Hiểu ngữ cảnh sâu
Sau khi lấy văn bản về, công nghệ Xử lý ngôn ngữ tự nhiên sẽ vào cuộc. AI sẽ đọc hiểu nội dung đó. Ví dụ, nó có thể phân biệt được từ “Apple” trong bài viết đang nói về quả táo hay tập đoàn công nghệ Apple, từ đó phân loại dữ liệu vào đúng danh mục.

Bước 3: Học hỏi và tự tối ưu (Reinforcement Learning)
Trong quá trình cào hàng triệu trang web, nếu gặp phải chướng ngại vật (như cấu trúc web lạ hoặc pop-up quảng cáo), AI sẽ tự thử nghiệm các cách xử lý khác nhau. Khi tìm ra cách vượt qua thành công, nó sẽ tự ghi nhớ để áp dụng cho các lần sau.
Ứng dụng đột phá của AI Crawler trong thực tế bao gồm?
Hiện nay, web scraping AI không còn là công cụ riêng của các kỹ sư công nghệ mà đã trở thành trợ thủ đắc lực cho nhiều hoạt động doanh nghiệp:

- Nghiên cứu thị trường và Theo dõi đối thủ: Tự động quét toàn bộ sản phẩm của đối thủ cạnh tranh để cập nhật biến động giá, chương trình khuyến mãi theo từng giờ.
- “Nuôi” các mô hình AI khác (LLM): Các siêu trí tuệ như ChatGPT hay Gemini cần một lượng dữ liệu khổng lồ để học tập. AI Crawler chính là những “chú ong chăm chỉ” đi gom nhặt kiến thức từ Internet về để huấn luyện các mô hình này.
- Lắng nghe mạng xã hội (Social Listening): Cào các bài viết, bình luận trên Facebook, TikTok, Reddit để phân tích tâm lý khách hàng (họ đang khen hay chê thương hiệu của bạn).
- Phân tích tài chính: Thu thập báo cáo tài chính, tin tức kinh tế từ hàng ngàn nguồn chính thống để giúp các quỹ đầu tư đưa ra dự báo thị trường chính xác.
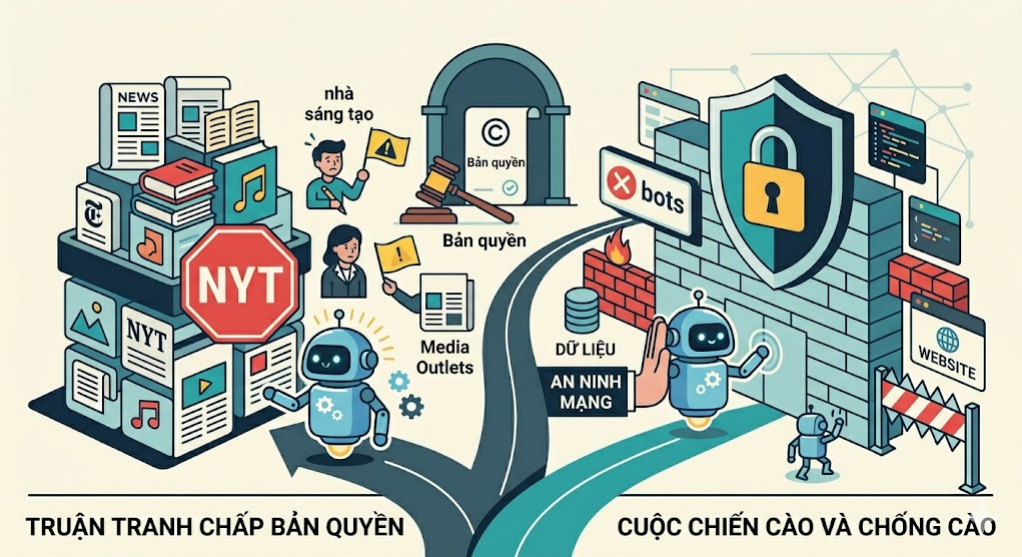
Những thách thức lớn của AI Crawler hiện nay là gì?
Mặc dù thông minh và tiện lợi, AI Crawler cũng đang đối mặt với những rào cản lớn về mặt pháp lý và kỹ thuật:
- Tranh chấp bản quyền dữ liệu: Nhiều nhà sáng tạo nội dung và các tờ báo lớn (như: The New York Times) đang khởi kiện các công ty AI vì hành vi cào dữ liệu không xin phép để huấn luyện mô hình.
- Cuộc chiến “Cào và Chống cào”: Các website lớn ngày càng thắt chặt an ninh bằng các tệp
robots.txtthế hệ mới nhằm chặn đứng các AI bot thu thập tài nguyên của họ.
Lời kết
Tóm lại, AI Crawler không chỉ đơn thuần là một công cụ nâng cấp từ phiên bản cũ, mà nó là một cuộc cách mạng trong cách nhân loại khai thác tri thức từ Internet. Sở hữu khả năng tự học, thích nghi và hiểu ngữ cảnh, AI Crawler đang mở ra kỷ nguyên thu thập dữ liệu tự động, chính xác và tinh vi hơn bao giờ hết.
Nếu doanh nghiệp của bạn đang tìm kiếm giải pháp tối ưu hóa dữ liệu hoặc xây dựng các mô hình phân tích thị trường, việc tiếp cận và ứng dụng công cụ cào dữ liệu AI ngay từ hôm nay sẽ là bước đi chiến lược để không bị bỏ lại phía sau.
