Trong bài này bạn sẽ học về
- Những câu lệnh phổ biến dùng trong thẻ meta robots
- Loại trừ tham số trong Webmaster Tools
- Robots.txt
Việc ngăn chặn máy tìm kiếm truy cập vào những nội dung bạn không muốn chúng truy cập và lưu dữ liệu cũng quan trọng như việc đảm bảo máy tìm kiếm có thể truy cập mọi nội dung quan trọng trên trang web của bạn. Tất cả các công ty tìm kiếm lớn đều tuân thủ theo tiêu chuẩn ngăn chặn máy tìm kiếm (giao thức hoạt động của robots) (https://en.wikipedia.org/wiki/Robots_exclusion_standard), có nghĩa rằng trước khi tìm hiểu nội dung website, chúng sẽ tìm đến file robots.txt, đọc nội dung ở đó để xem chúng có thể ghé thăm khu vực nào trên website. Để sử dụng hiệu quả các công cụ này, bạn cần hiểu biết nhất định để phân biệt sự khác nhau giữa dò quét và lưu dữ liệu.
Meta name=”robots”
Index,follow
Mặc định tất cả các trang trên website đều nhận thuộc tính là “index,follow”. Nó có nghĩa là “bổ sung, lưu trữ trang này vào cơ sở dữ liệu và lần theo những đường link trên trang này nếu những đường link này không bị đặt thuộc tính nofollow.
Vì là mặc định nên bạn không cần chèn tag meta này trên trang web. Tuy nhiên một vài loại CMS sẽ tự động chèn tag này vào code. Cấu trúc HTML của thuộc tính này là:
<META NAME=”ROBOTS” CONTENT=”INDEX, FOLLOW”>
Thẻ này được đặt trong 2 thẻ <head> và </head> của một trang web, khi xem code của một trang web HTML bất kỳ, bạn sẽ thấy code của nó tương tự như mẫu dưới đây:
<html>
<head>
<title>Tên trang</title>
<META NAME=”ROBOTS” CONTENT=”INDEX, FOLLOW”>
</head>
Noindex,Follow
Đọc tiêu đề bạn cũng hiểu, “noindex” có nghĩa là chúng ta yêu cầu máy tìm kiếm không lưu dữ liệu trang web này (mặc dù chúng có thể dò quét nó). “Follow” cho máy tìm kiếm biết chúng ta muốn chúng lần theo những đường link trên trang web này. Thiết lập này đặc biệt phù hợp khi chúng ta không muốn máy tìm kiếm xếp hạng những trang web này nhưng chúng ta cần máy tìm kiếm dò quét và khám phá những trang web khác mà trang web này đang đặt liên kết trỏ tới. Khi chúng ta có quá nhiều thông tin, sản phẩm hoặc dịch vụ mà cần phải phân chia thành nhiều trang web, chúng ta thường sử dụng thiết lập này. Cấu trúc HTML của thuộc tính này là:
<meta name=”robots” content=”NOINDEX, FOLLOW”>
Noindex,NoFollow
Thẻ này rất hiếm khi được sử dụng. Thông thường bạn muốn bọ tìm kiếm lần theo tất cả các liên kết trên trang web kể cả khi bạn không muốn trang web đó xuất hiện trên bảng kết quả tìm kiếm. Lưu ý rằng, kể cả khi một trang không được index – không được lưu vào CSDL của Google, nó vẫn có thể truyền link juice (hay sức mạnh của link). Dù vậy, có một vài trường hợp mà bạn sẽ muốn sử dụng thuộc tính “noindex,nofollow”. Ví dụ, nếu tất cả các liên kết trên trang đều trỏ đến những nội dung trùng lặp, hoặc nếu nội dung đó do người dùng viết ra và chưa qua kiểm duyệt và do đó có thể bị lạm dụng cho mục đích xấu, bạn sẽ muốn noindex, nofollow tất cả những trang này.
Một chú ý cuối cùng về việc sử dụng thẻ Meta robots. Mặc định, meta robots áp dụng với tất cả các loại robots. Nếu bạn chỉ muốn chặn một hoặc một vài loại robots cụ thể nào đó, bạn có thể thay thế “robots” bằng tên của con bọ tìm kiếm mà bạn muốn chặn. Ví dụ, bạn muốn googlebot không index trang web nhưng follow theo tất cả các link trên trang web đó, hãy sử dụng cấu trúc sau:
<meta name=”Googlebot” content=”INDEX, FOLLOW”>
Trang web dưới đây liệt kê tên của tất cả các loại bọ tìm kiếm: robotstxt.org
Cài đặt Webmaster Tools
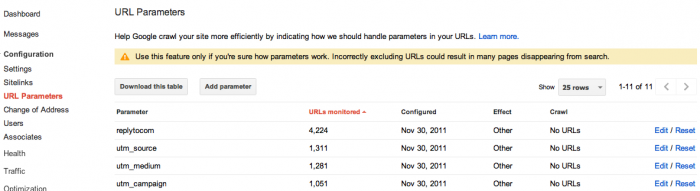
Bộ công cụ quản trị Web của cả Bing và Google (Webmaster Tools) giờ đây có chức năng giúp bạn hướng dẫn Google cách xử lý với các trang web có chứa tham số, thứ mà trước kia có thể gây nhầm lẫn với máy tìm kiếm. Chi tiết bạn có thể tham khảo dưới đây:
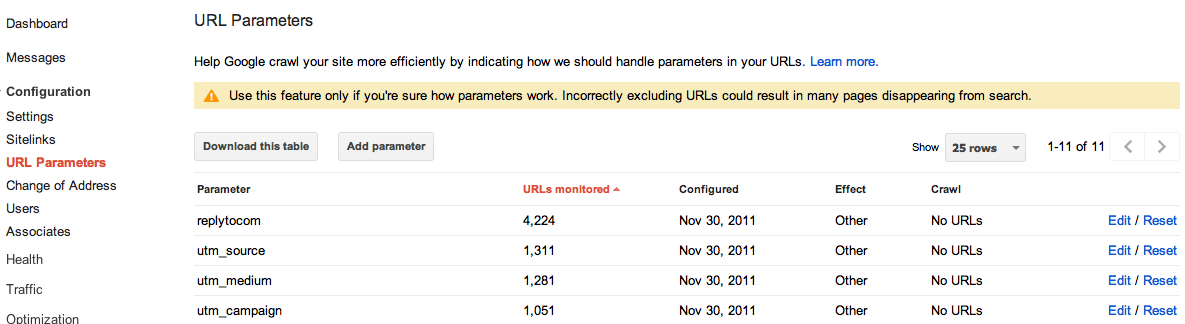
Google Webmaster Tools
Truy cập vào tài khoản Google Webmaster Tools của bạn, click vào “Configuration” sau đó là “URL Parameters” như hình dưới đây:
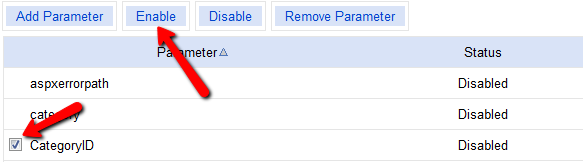
Bing Webmaster Tools
Robots.txt
File robots.txt là một loại file văn bản, con người có thể đọc hiểu được, và được đặt ở thư mục gốc của website, do vậy máy tìm kiếm có thể dễ dàng tìm thấy và hiểu được nội dung của nó. Vị trí của file này thông thường đặt tại, và nó dùng để chặn bọ tìm kiếm khỏi dò quét và lưu dữ liệu trên website của bạn.
Câu cuối cùng này là câu rất quan trọng mà tôi cần phải nhắc lại một lần nữa. Nếu bạn chặn một địa chỉ URL, tất cả các thư mục con và các trang web trong thư mục này đều bị chặn. Máy tìm kiếm sẽ hoàn toàn bỏ qua những trang này cũng như tất cả những link nằm trên chúng. Cụ thể, bất kỳ thiết lập meta robots nào mà bạn đã học được ở trên cũng sẽ bị bỏ qua.
Định dạng cơ bản của Robots.txt
Định dạng cơ bản của file robots.txt là
User-agent: *
Disallow: *
Sitemap:
Những phần chính là:
User-agent: Đây là vị trí mà bạn điền tên của con bọ tìm kiếm mà bạn muốn điều khiển. Nếu bạn muốn chặn tất cả các loại bọ, chỉ cần thay tên của chúng bằng ký tự đại diện là *. Khi đó dòng lệnh sẽ có dạng: User-agent: *
Allow: Đây là nơi bạn điền địa chỉ những trang web bạn muốn index. Nếu bạn muốn chúng index tất cả các trang web trên website, sử dụng dấu xược trước “/”, hoặc bạn có thể đơn giản để trống chúng.
Disallow: Đây là nơi bạn điền địa chỉ những trang web mà bạn muốn chặn bọ tìm kiếm truy cập vào. Ví dum, nếu bạn không muốn bọ tìm kiếm dò quét và lưu dữ liệu khi vực Admin, hãy đặt “/admin”.
Khi đó ta có cấu trúc như sau: Disallow: /admin. Câu lệnh này sẽ chặn tất cả các files trong thư mục Admin. Cụ thể những địa chỉ sau đây sẽ bị chặn truy cập : “https://www.domain.com/admin/login” or “https://www.domain.com/admin/secretfile”.
Lưu ý rằng, mỗi địa chỉ URL hoặc tên thư mục phải được đặt ở 1 dòng riêng.
Sitemap: Đây là nơi bạn đặt địa chỉ của file sitemap.xml. Ví dụ
Sitemap: https://www.domain.com/sitemap.xml.
Như bạn đã biết, bạn có thể sử dụng nhiều sitemap trên một website để tiện quản lý. Bạn có thể tham khảo danh sách các sitemap của CNN tại đây : CNN’srobots.txt. Như bạn thấy họ có sitemap dành riêng cho mục tin tức (News) và sitemap riêng cho Video.
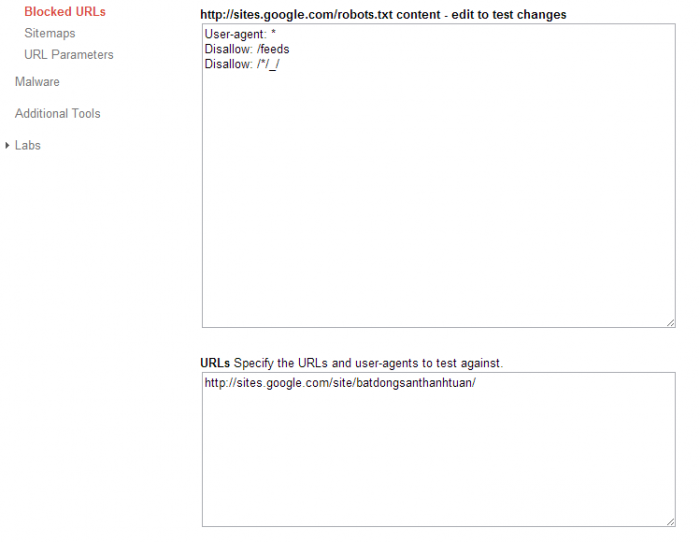
Kiểm tra File Robots.txt trong Webmaster Tools
Webmaster Tools hỗ trợ bạn kiểm tra cấu trúc của file robots.txt, để đảm bảo bạn không chặn những trang quan trọng, ví dụ Trang chủ.
Để làm điều này, Vào Crawl => Blocked URLs trong Webmaster Tools
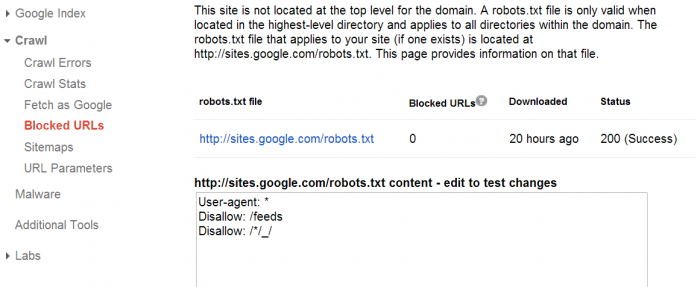
Sử dụng 2 hộp dưới đây (dưới danh sách sitemap), bạn có thể chỉnh sửa file robots.txt trước khi lưu nó lại. Lưu ý kiếm tra lại một lần nữa để tránh trường hợp các trang web quan trọng bị chặn.
Nếu bạn muốn xem quan điểm của Google về việc chặn bọ tìm kiếm, ghé thăm bài viết này https://support.google.com/webmasters/bin/answer.py?hl=en&answer=93708
Bài tập:
- Nêu những khác biệt chính giữa thẻ meta robots và file robots.txt
Tìm hiểu thêm các cách làm khác hoặc tham khảo khóa học seo của VietMoz để được hệ thống hóa các kiến thức một cách bài bản.
Nguồn: www.vietmoz.edu.vn
Bản quyền thuộc về Đào tạo SEO VietMoz
Vui lòng không copy khi chưa được sự đồng ý của tác giả

{kind=link}