
Hiểu được ngôn ngữ con người là một thử thách lớn, ngay cả với chính con người, chứ đừng nói đến máy tính. Ngôn ngữ đầy rẫy sự mơ hồ, ngữ cảnh khác biệt, ẩn dụ và cách diễn đạt đa nghĩa. Khi đọc một câu, chúng ta thường dựa vào kinh nghiệm, trực giác và tri thức nền để hiểu. Nhưng với máy, tất cả điều này cần được “mô phỏng” bằng thuật toán và dữ liệu.
Một trong những bước quan trọng giúp máy hiểu ngôn ngữ là xác định chính xác thực thể mà văn bản đang nhắc đến, ví dụ như con người, địa điểm, tổ chức hay khái niệm. Sau đó, hệ thống sẽ liên kết thực thể này với một định danh duy nhất trong cơ sở tri thức. Toàn bộ quy trình đó gọi là entity linking, và nó chính là cầu nối giữa “từ ngữ” và “tri thức có cấu trúc”.
Vì sao Entity Linking lại cần thiết?
Hãy thử xem ví dụ:
“Jordan chơi rất hay trong trận gặp Phoenix tối qua.”
Câu này nghe đơn giản, nhưng với máy, lại cực kỳ khó hiểu. “Jordan” là ai? Michael Jordan, cầu thủ bóng rổ huyền thoại, hay một vận động viên khác? Còn “Phoenix” là đội bóng, hay thành phố ở Arizona? Chỉ khi hiểu được ngữ cảnh, máy mới có thể chọn đúng “Jordan” và “Phoenix” cần liên kết đến trong cơ sở tri thức.
Để làm được điều này, entity linking cần tận dụng ngữ cảnh (ví dụ như từ “chơi” gợi ý rằng đây là tình huống thể thao) để loại bỏ các khả năng sai và xác định đúng thực thể. Nói cách khác, đây là công việc giải mơ hồ, kỹ năng mà con người làm theo bản năng, còn máy thì phải “học”.
Vai trò của entity linking trong xử lý ngôn ngữ tự nhiên
Entity linking là nền tảng của rất nhiều ứng dụng trong NLP. Khi văn bản được “hiểu” ở mức thực thể, mọi thứ trở nên dễ truy cập, dễ tổ chức và dễ phân tích hơn. Một số ứng dụng điển hình bao gồm:
Cải thiện tìm kiếm ngữ nghĩa
Entity linking giúp hệ thống hiểu đúng thực thể mà người dùng nhắc đến trong câu truy vấn. Ví dụ: Khi người dùng tìm kiếm từ khóa “Hà Nội”, hệ thống không chỉ nhận diện đó là tên một thành phố mà còn phân biệt đây là thủ đô của Việt Nam chứ không phải tên một quán cà phê hay khu vực khác. Việc này giúp kết quả tìm kiếm chính xác và sát với ý định thực tế của người dùng.
Ngoài ra, hệ thống cũng có thể gợi ý các địa danh liên quan như “Thủ đô”, “Hồ Hoàn Kiếm” hoặc các thành phố khác như “Hồ Chí Minh”. Điều này giúp người dùng có trải nghiệm tìm kiếm phong phú và thuận tiện hơn khi khám phá thông tin.
Khai thác và mở rộng tri thức
Entity linking biến dữ liệu văn bản tự nhiên thành dữ liệu có cấu trúc bằng cách gán các thực thể với các mục trong cơ sở tri thức. Ví dụ, khi nhắc đến “Nguyễn Tấn Dũng”, hệ thống liên kết được đây là tên một cựu Thủ tướng Việt Nam, từ đó tự động phát hiện mối quan hệ với các tổ chức khác như “Chính phủ Việt Nam”.
Việc này cho phép hệ thống tổng hợp thông tin về các thực thể và mở rộng tri thức liên quan như chính sách, sự kiện hoặc các thuộc tính liên quan. Từ đó, có thể xây dựng cơ sở dữ liệu phong phú phục vụ cho phân tích, nghiên cứu và ứng dụng quản lý tri thức.
Phân tích ngữ nghĩa và gợi ý nội dung
Khi entity linking xác định chính xác thực thể trong văn bản Việt Nam, hệ thống có thể phân tích cảm xúc và ngữ nghĩa sâu hơn. Ví dụ, khi biết bài viết đề cập đến “Hội An” hệ thống có thể nhận diện cảm xúc tích cực hoặc tiêu cực liên quan đến du lịch tại địa phương này. Ngoài ra, hệ thống có thể đề xuất các bài viết cùng chủ đề như “Du lịch Đà Nẵng” hoặc bài viết về văn hóa “Ẩm thực miền Trung” giúp người đọc có trải nghiệm cá nhân hóa và phong phú hơn.
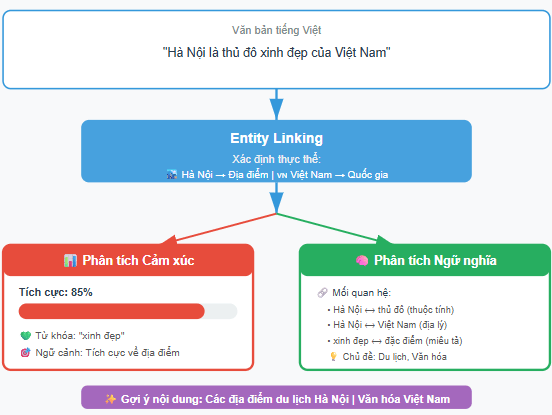
Truy vấn ngôn ngữ tự nhiên và RAG
Trong các hệ thống chatbot hoặc trợ lý ảo tiếng Việt, entity linking giúp xác định đúng thực thể khi người dùng đặt câu hỏi. Ví dụ, khi người dùng hỏi: “Thủ đô Việt Nam là gì?”, hệ thống nhận diện thực thể “Thủ đô Việt Nam” và trả về câu trả lời chính xác là “Hà Nội”.
Kết hợp với mô hình Retrieval – Augmented Generation, chatbot có thể dựa trên thông tin thực tế và kiến thức mở rộng để cung cấp câu trả lời chính xác, giúp cải thiện trải nghiệm người dùng và tăng độ tin cậy cho hệ thống AI.
Các hướng tiếp cận trong entity linking
Entity linking có hai hướng tiếp cận phổ biến nhất: tiếp cận từ đầu đến cuối và tiếp cận chỉ phân giải mơ hồ thực thể. Mỗi hướng có vai trò khác nhau trong việc giúp hệ thống hiểu và liên kết thực thể chính xác.
Tiếp cận từ đầu đến cuối (end-to-end)
Trong cách tiếp cận này, hệ thống vừa nhận diện thực thể trong văn bản vừa liên kết chúng với mục tương ứng trong cơ sở tri thức. Máy học biểu diễn ngữ cảnh của từng thực thể và so sánh với các mục trong knowledge base để tìm ra đối tượng khớp nhất. Nhờ làm cả hai bước trong một quy trình, thông tin được xử lý liền mạch và giảm thiểu sai lệch giữa các giai đoạn.
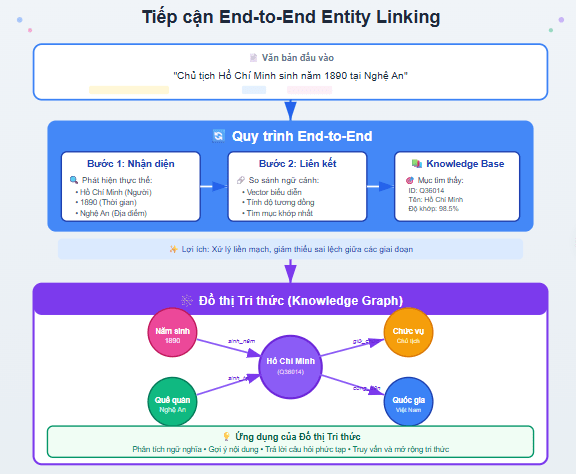
Khi thực thể được liên kết, dữ liệu sẽ được đưa vào đồ thị tri thức nhằm tổ chức và kết nối thông tin một cách có cấu trúc. Điều này giúp hệ thống dễ dàng truy vấn, mở rộng tri thức và phân tích mối quan hệ giữa các thực thể. Nhờ vậy, các ứng dụng như phân tích ngữ nghĩa, gợi ý nội dung hay trả lời câu hỏi phức tạp hoạt động chính xác và hiệu quả hơn.
Tiếp cận chỉ phân giải mơ hồ thực thể (entity disambiguation)
Ở hướng tiếp cận này, hệ thống chỉ tập trung vào việc phân biệt thực thể, giả định rằng bước nhận diện thực thể đã được thực hiện từ trước (ví dụ bằng NER). Mục tiêu là xác định đúng thực thể trong knowledge base dựa trên ngữ cảnh xuất hiện, giúp tránh nhầm lẫn giữa các thực thể trùng tên. Đây là cách xử lý tối ưu khi muốn tăng độ chính xác ở bước chọn thực thể.
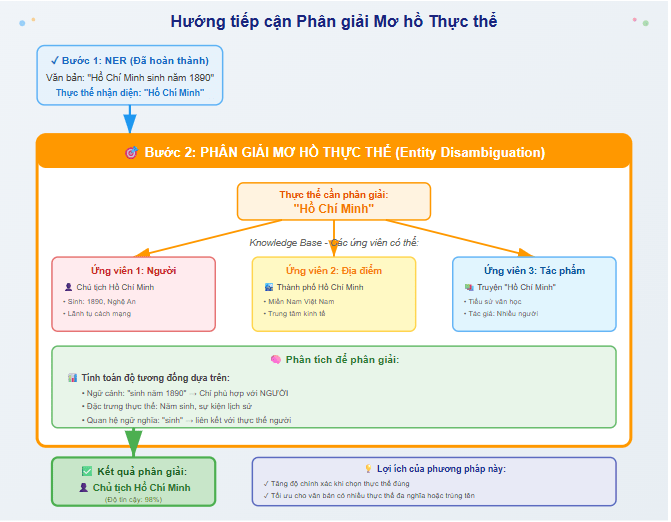
Quá trình phân giải mơ hồ dựa trên việc tính toán độ tương đồng giữa thực thể được nhắc tới và các ứng viên có thể có. Hệ thống sử dụng thông tin ngữ cảnh, đặc trưng của từng thực thể và quan hệ ngữ nghĩa để đưa ra lựa chọn đúng nhất. Cách tiếp cận này đặc biệt quan trọng trong các văn bản chứa nhiều thực thể đa nghĩa hoặc dễ gây nhầm lẫn.
Quy trình triển khai entity linking
Entity linking biến những từ ngữ rời rạc trong văn bản thành thực thể có ý nghĩa, giúp máy hiểu và khai thác thông tin như con người. Quy trình cơ bản gồm hai giai đoạn chính.
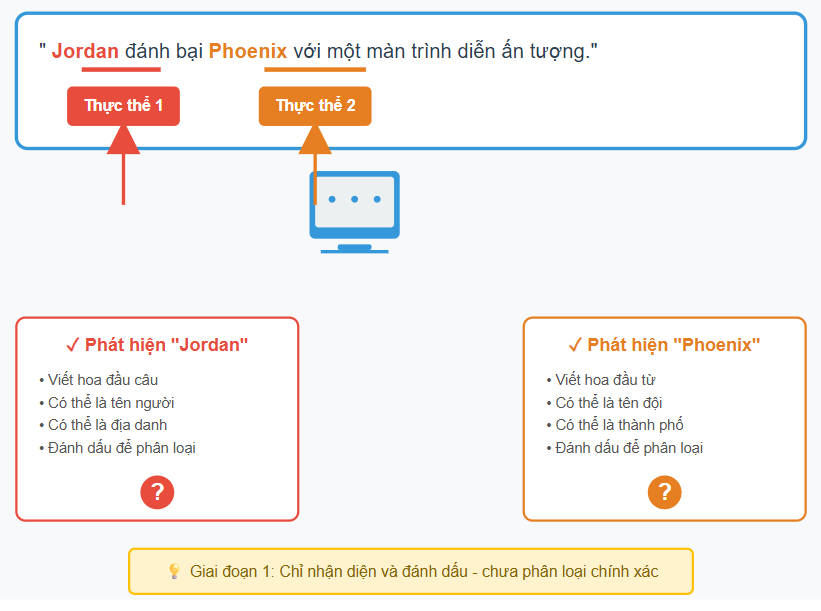
Nhận diện thực thể:
Hãy tưởng tượng bạn đọc một câu:
“Jordan defeated Phoenix with an impressive performance.”
Ngay lập tức, mắt bạn nhận ra “Jordan” và “Phoenix” là những từ quan trọng. Máy cũng làm điều tương tự. Trước tiên, nó nhìn qua từng từ, từng cụm từ, và đánh dấu những ứng viên có khả năng là thực thể, chẳng hạn tên người, địa điểm hay tổ chức.
Ở bước này, hệ thống chỉ cần nhận diện sơ bộ: biết rằng đây là những từ cần chú ý, giống như bạn đang highlight các nhân vật hoặc địa danh trong một câu chuyện. Nó chưa cần biết chính xác là ai hay ở đâu mà chỉ cần đánh dấu ra.
Giải mơ hồ và liên kết thực thể:
Sau khi đã đánh dấu các từ quan trọng, máy bắt đầu tìm danh tính thực sự của chúng. Lấy ví dụ “Jordan”: đó có thể là Michael Jordan, quốc gia Jordan, hay dòng sông Jordan.
Hệ thống sẽ hoạt động như một nhà thám hiểm: nhìn xung quanh từ “Jordan”, đọc ngữ cảnh của câu, từ “defeated” và “performance” gợi ý rằng đây là một vận động viên, không phải quốc gia hay dòng sông. Sau đó, máy tìm đến cơ sở tri thức (ví dụ Wikidata), và liên kết “Jordan” với Michael Jordan (một định danh duy nhất, rõ ràng).
Tương tự với “Phoenix”, máy sẽ xác định đó là đội bóng Phoenix thay vì thành phố hay thần thoại. Khi tất cả các thực thể được liên kết, văn bản không còn là chuỗi chữ rời rạc mà trở thành một mạng lưới thông tin có nghĩa, sẵn sàng để phân tích, truy vấn hoặc khai thác tri thức.
Knowledge graph có phải là nền tảng của entity linking không?
Có. Knowledge Graph chính là nền tảng quan trọng của entity linking.
Nó hoạt động như “bộ não tri thức”, lưu trữ toàn bộ thông tin về thực thể, bao gồm tên gọi, thuộc tính, quan hệ và ngữ cảnh liên quan, tất cả đều được tổ chức theo dạng mạng lưới có cấu trúc. Nhờ cấu trúc này, hệ thống có thể tra cứu và đối chiếu thực thể một cách chính xác hơn.
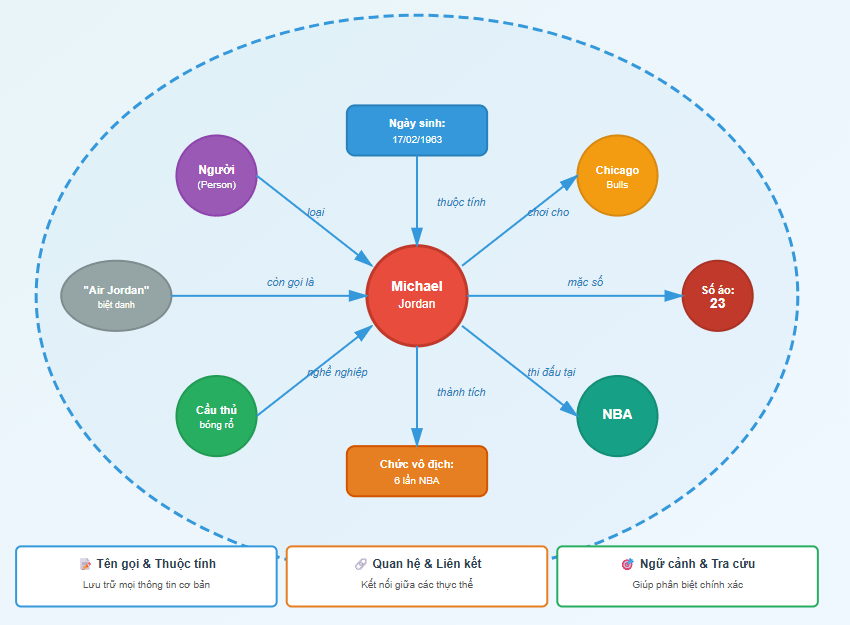
Khi gặp một tên gọi mơ hồ như “Jordan”, hệ thống có thể truy vào knowledge graph và xem các kết nối như “Michael Jordan → NBA → Chicago Bulls → basketball”. Từ đó, mô hình dễ dàng suy luận rằng đây là con người, chứ không phải quốc gia hay dòng sông. Chính các mối quan hệ trong graph đã giúp làm rõ ngữ nghĩa mà văn bản một mình không thể cung cấp.
Các mô hình mới còn tận dụng trực tiếp dữ liệu trong knowledge graph thông qua Graph Neural Network hoặc embedding của đồ thị. Điều này giúp máy hiểu sâu “ngữ nghĩa kết nối”, nghĩa là nó hiểu tại sao hai thực thể liên quan, chứ không chỉ hiểu từ ngữ đơn lẻ.
Khi entity linking và knowledge graph phối hợp, chúng tạo thành một vòng tăng cường liên tục: Knowledge graph giúp mô hình liên kết thực thể chính xác hơn, và mô hình lại bổ sung thêm các thực thể hoặc quan hệ mới để làm giàu graph. Nhờ vậy, chất lượng tri thức và độ chính xác của entity linking ngày càng được cải thiện.
Kết luận
Entity linking là một nhiệm vụ cốt lõi trong xử lý ngôn ngữ tự nhiên. Nó giúp biến văn bản thô thành tri thức có cấu trúc. Khi kết hợp với knowledge graph, quá trình này không chỉ giúp máy “hiểu” nội dung tốt hơn, mà còn tự làm giàu tri thức qua thời gian. Từ việc cải thiện tìm kiếm, khai thác dữ liệu đến trợ lý AI, entity linking chính là chìa khóa để biến dữ liệu ngôn ngữ thành hệ thống hiểu biết thực sự. Nó không chỉ giúp máy hiểu con người hơn, mà còn giúp con người hiểu chính tri thức của mình sâu sắc hơn.
