
Cách sử dụng Python dự báo lượng truy cập, nhu cầu cho SEO. Những dự báo này có thể đem lại giá trị lớn trong SEO. Dưới đây là cách nhận được dữ liệu về các xu hướng có thể có trong tìm kiếm trong tương lai mà không phải trả tiền thông qua Python.
Cho dù đó có là nhu cầu tìm kiếm, doanh thu hay là lưu lượng truy cập từ tìm kiếm không phải trả tiền. Tại một số thời điểm trong sự nghiệp làm SEOer, bạn sẽ được yêu cầu đưa ra dự báo nào đó.
Trong bài viết này, bạn sẽ học được cách thực hiện điều đó một cách chính xác và hiệu quả nhờ Python.
Chúng ta sẽ khám phá cách:
- Kéo và vẽ dữ liệu.
- Sử dụng các phương pháp tự động để ước tính được các thông số mô hình phù hợp nhất.
- Áp dụng phương pháp Augmented Dickey-Fuller (ADF) để kiểm tra thống kê tại một chuỗi thời gian.
- Ước tính số lượng thông số cho một mô hình SARIMA.
- Kiểm tra các mô hình của bạn và đưa ra dự báo.
- Diễn giải và đưa ra kết quả dự báo của bạn.
Trước khi chúng ta đi sâu vào bài viết này, hãy tập xác định dữ liệu. Cho dù đó là loại chỉ số nào và dữ liệu đó sẽ xảy ra theo thời gian.
Trong hầu hết các trường hợp, điều này có thể được diễn ra trong một loạt các ngày. Vô cùng hiệu quả, các kỹ thuật mà mình sẽ chia sẻ ở đây là các kỹ thuật dữ báo chuỗi thời gian.
Vậy tại sao phải dự báo?
Để trả lời được câu hỏi này, mình sẽ đặt ra một câu hỏi ngược lại: “Tại sao bạn lại không dự báo?”
Những kỹ thuật này đều đã được sử dụng từ lâu trong lĩnh vực tài chính đối với giá cổ phiếu và nhiều lĩnh vực khác. Vậy tại sao SEO lại phải khác biệt?

Với những mối quan tâm như người đang nắm giữ ngân sách và các đồng nghiệp khác, ở đây chả hạn như giám đốc SEO và giám đốc tiếp thị – sẽ có những kỳ vọng nhất định về những gì kênh tìm kiếm không phải trả tiền có thể cung cấp và liệu những kỳ vọng đó có được đáp ứng một cách tốt nhất hay không?
Và đương nhiên, dự báo sẽ cung cấp câu trả lời đó dựa theo hướng dữ liệu.
Thông tin dự báo hữu ích dành cho các chuyên gia SEO
Khi sử dụng phương pháp tiếp cận dựa theo hướng dữ liệu bằng Python, có một số điều mà các SEOer cần phải lưu ý:
Dự báo hoạt động tốt nhất khi có nhiều dữ liệu lịch sử.
Nhịp độ của dữ liệu sẽ xác định được khung thời gian cần thiết cho dự báo của bạn.
Ví dụ: Nếu như bạn có thêm dữ liệu hàng ngày giống như bạn làm trong phân tích trang web của mình thì bạn sẽ có hơn 720 điểm dữ liệu, và điều này hoàn toàn tốt.
Còn đối với Google Xu hướng (Google Trends), có nhịp độ hàng tuần thì bạn sẽ cần ít nhất 5 năm để có được 250 điểm dữ liệu.
Trong mọi trường hợp, bạn nên nhắm tới một khung thời gian cung cấp cho bạn ít nhất khoảng 200 điểm dữ liệu.
Mô hình thích sự nhất quán.

Nếu xu hướng dữ liệu của bạn có dạng mô hình – ví dụ như nó có tính chu kỳ vì tính thời vụ – thì các dự báo của bạn có nhiều khả năng đáng tin cậy hơn.
Do đó, các dự báo thường không xử lý tốt các xu hướng đột phá vì không có dữ liệu lịch sử để làm cơ sở cho tương lai, cái này mình sẽ giải thích ở phần sau.
Vậy câu hỏi được đặt ra, các mô hình dự báo sẽ hoạt động như thế nào? Có một số khía cạnh mà mô hình sẽ giải quyết về dữ liệu chuỗi thời gian:
Tự tương quan
Tự tương quan là mức độ mà điểm dữ liệu tương tự đối với điểm dữ liệu đã có trước đó.
Điều này có thể cung cấp cho mô hình của bạn thông tin về mức độ ảnh hưởng của một sự kiện trong một khoảng thời gian đối với lưu lượng tìm kiếm và liệu mô hình đó có thay đổi theo mùa hay không.
Tính thời vụ
Tính thời vụ sẽ thông báo cho mô hình biết liệu rằng có một mô hình theo chu kỳ không và các thuộc tính của mô hình đó.
Ví dụ như, thời lượng hoặc kích thước của sự thay đổi giữa mức cao nhất và mức thấp nhất.
Tính ổn định
Tính ổn định là thước đo xu hướng tổng thể đang thay đổi như thế nào theo thời gian. Xu hướng không cố định sẽ cho thấy xu hướng chung đang lên hay đang đi xuống, bất chấp mức cao và mức thấp của chu kỳ dựa theo mùa.
Khám phá kho dữ liệu của bạn
# Import your libraries
import pandas as pd
from statsmodels.tsa.statespace.sarimax import SARIMAX
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.seasonal import seasonal_decompose
from sklearn.metrics import mean_squared_error
from statsmodels.tools.eval_measures import rmse
import warnings
warnings.filterwarnings(“ignore”)
from pmdarima import auto_arima
Chúng ta sẽ sử dụng dữ liệu trên Google Trends, đây là một bản xuất dưới dạng CSV.
Những kỹ thuật này hoàn toàn có thể sử dụng trên bất kỳ dữ liệu chuỗi thời gian nào. có thể là dữ liệu của riêng bạn, số lần nhấp chuột, doanh thu của khách hàng hay của công ty bạn,…
# Import Google Trends Data
df = pd.read_csv(“exports/keyword_gtrends_df.csv”, index_col=0)
df.head()
Các dữ liệu từ Google Trends là một chuỗi thời gian rất đơn giản (được tính theo ngày), các truy vấn và lượt truy cập kéo dài trong khoảng thời gian 5 năm.
Đã tới lúc định dạng khung dữ liệu từ dài sang rộng.
Điều này sẽ cho phép chúng ta xem dữ liệu với mỗi truy vấn tìm kiếm dưới dạng các cột:
df_unstacked = ps_trends.set_index([“date”, “query”]).unstack(level=-1)
df_unstacked.columns.set_names([‘hits’, ‘query’], inplace=True)
ps_unstacked = df_unstacked.droplevel(‘hits’, axis=1)
ps_unstacked.columns = [c.replace(‘ ‘, ‘_’) for c in ps_unstacked.columns]
ps_unstacked = ps_unstacked.reset_index()
ps_unstacked.head()
Chúng ta không còn cột số lần truy cập nữa, vì đây là các giá trị của các truy vấn trong các cột tương ứng của chúng.
Định dạng này không chỉ hữu ích cho SARIMA, mà còn hữu ích cho các mạng lưới Long short-term memory (LSTM).
Hãy cùng xem các dữ liệu:
ps_unstacked.plot (figsize = (10,5))
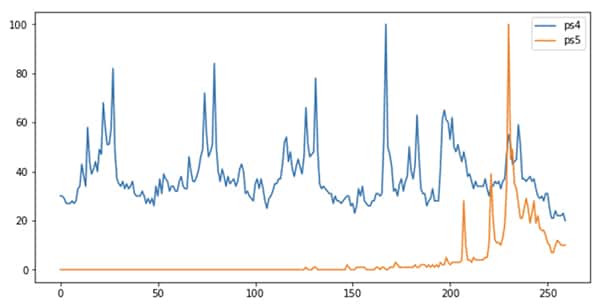
Từ biểu đồ ở trên, bạn sẽ thấy được rằng, cấu hình của “PS4” và “PS5” đều khác nhau.
Đối với những ai không phải là game thủ hay chưa biết về “PS4”, thì đây là thế hệ thứ 4 của máy chơi game Sony PlayStation và “PS5” là thế hệ thứ 5.
Các tìm kiếm trên “PS4” có tính thời vụ cao hơn vì chúng là một sản phẩm đã được ra mắt, bày bán và độ phủ tương đối ổn định cho tới khi mà “PS5” xuất hiện (ở phần cuối).
Do “PS5” không tồn tại cách đây 5 năm, vậy nên việc không xuất hiện trên Google Trends trong 4 năm đầu tiên cũng là một điều tương đối dễ hiểu trong biểu đồ.
Phân rã xu hướng
Bây giờ, chúng ta sẽ phân tích các đặc điểm dựa theo mùa (Seasonal) hoặc không theo mùa của từng xu hướng:
ps_unstacked.set_index (“date”, inplace = True)
ps_unstacked.index = pd.to_datetime (ps_unstacked.index)
và
query_col = ‘ps5’
a = season_decompose (ps_unstacked [query_col], model = “add”)
a.plot ();
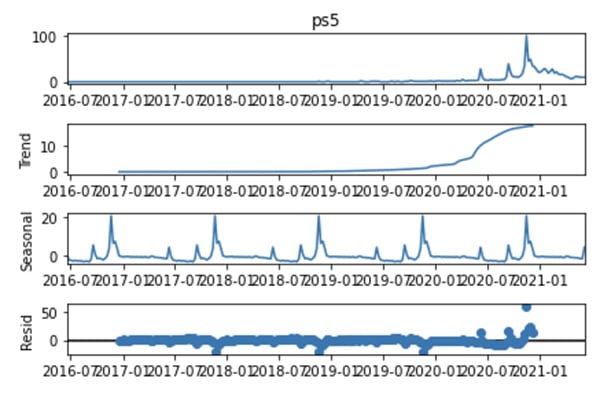
Ở biểu đồ trên cho thấy dữ liệu chuỗi thời gian và xu hướng đều đều cho tới khi xuất hiện phát sinh vào năm 2020.
Mục xu hướng theo mùa (Seasonal) hiển thị các đỉnh lặp đi lặp lại, điều này có thể thấy rằng tính xuất hiện theo thời vụ của nó từ năm 2016. Tuy nhiên, có vẻ nó không đáng tin cậy cho lắm khi mà trong suốt chuỗi thời gian từ 2016 đến 2020 đều bằng phẳng.
Phần dư (Resid) hiển thị bất kỳ mẫu nào còn lại của dữ liệu chuỗi thời gian sau khi tính đến tính thời vụ và xu hướng, trên thực tế là “PS5” đều không có gì cho tới năm 2020 vì nó hầu như đều là con số 0.
Còn đối với “PS4”:
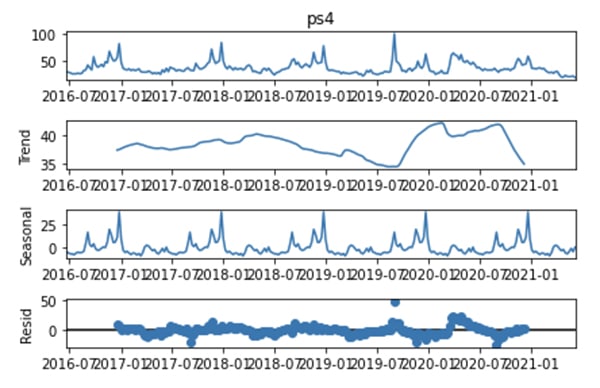
Chúng ta có thể thấy rõ được sự biến động trong ngắn hạn (Seasonal) và dài hạn (Trend) cùng với một số nhiễu (Resid).
Bước tiếp theo chúng ta sẽ sử dụng phương pháp Augmented Dickey-Fuller (ADF) để kiểm tra, thống kê xem một chuỗi thời gian nhất định có đứng yên hay thay đổi gì hay không.
from pmdarima.arima import ADFTest
adf_test = ADFTest(alpha=0.05)
adf_test.should_diff(ps_unstacked[query_col])
PS4: (0.09760939899434763, True)
PS5: (0.01, False)
Chúng ta có thể thấy giá trị “p” của “PS4” được hiển thị ở trên là hơn 0,05. Điều đó có nghĩa là dữ liệu chuỗi thời gian không cố định và do đó, cần phải có sự khác biệt.
Mặt khác “PS5” nhỏ hơn 0,05 và ở mức 0,01. Điều này có nghĩa là nó cố định và không yêu cầu sự khác biệt.
Mục đích của tất cả các điều này là để giúp bạn hiểu được các thông số sẽ được sử dụng nếu xây dựng mô hình dự báo các tìm kiếm trên Google theo cách thủ công.
Phù hợp với mô hình SARIMA của bạn
Vì chúng ta sẽ sử dụng các phương pháp tự động nhằm ước tính các thông số mô hình phù hợp nhất (sau này), nên bây giờ chúng ta sẽ ước tính số lượng thông số cho mô hình SARIMA.
Vì sao lại lựa chọn SARIMA? Đơn giản vì nó dễ cài đặt.
Ở trong mọi trường hợp, SARIMA có khả năng so sánh khá tốt với Prophet về độ chính xác.
Để có thể ước tính các thông số cho mô hình SARIMA, hãy lưu ý rằng ở đây mình đã đặt m thành 52 vì có 52 tuần ở trong một năm và đây cũng là các khoảng thời gian được phân chia trong Google Trends.
Chúng ta sẽ đặt tất cả các tham số bắt đầu từ 0 để có thể cho phép auto_arima thực hiện công việc vất vả nhất và tìm kiếm các giá trị phù hợp nhất với dữ liệu để có thể dự báo.
ps5_s = auto_arima(ps_unstacked[‘ps4’],
trace=True,
m=52, # there are 52 periods per season (weekly data)
start_p=0,
start_d=0,
start_q=0,
seasonal=False)
Phản hồi ở trên:
Performing stepwise search to minimize aic
ARIMA(3,0,3)(0,0,0)[0] : AIC=1842.301, Time=0.26 sec
ARIMA(0,0,0)(0,0,0)[0] : AIC=2651.089, Time=0.01 sec
…
ARIMA(5,0,4)(0,0,0)[0] intercept : AIC=1829.109, Time=0.51 sec
Best model: ARIMA(4,0,3)(0,0,0)[0] intercept
Total fit time: 6.601 seconds
Bản in ở trên cho thấy các thông số nhận được kết quả tốt nhất là:
PS4: ARIMA(4,0,3)(0,0,0)
PS5: ARIMA(3,1,3)(0,0,0)
Ước tính PS5 sẽ được chi tiết hơn khi in ra bản tóm tắt mô hình:
ps5_s.summary()
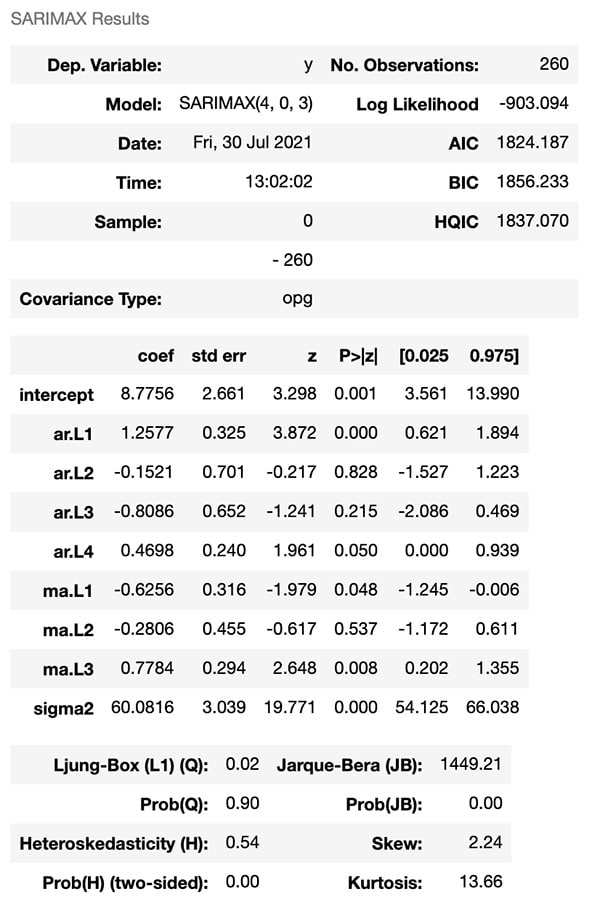
Hiện đang xảy ra điều thế này: Các chức năng đang tìm cách nhằm giảm thiểu xác suất lỗi được đo lường bởi cả Tiêu chí Thông tin của Akaike (AIC) và Tiêu chí Thông tin Bayesian.
AIC = -2Log (L) + 2 (p + q + k + 1)
Với điều kiện L là khả năng xảy ra của dữ liệu, k = 1 nếu c ≠ 0 và k = 0 nếu c = 0
BIC = AIC + [log (T) – 2] + (p + q + k + 1)
Bằng cách giảm thiểu AIC và BIC, chúng tôi nhận được các tham số ước tính tốt nhất dành cho p và q.
Kiểm tra mô hình
Bây giờ, chúng ta đã có được các thông số và có thể bắt đầu đưa ra được dự báo.
Đầu tiên, chúng ta sẽ xem mô hình hoạt động như thế nào đối với các dữ liệu trong quá khứ. Điều này cung cấp một số dấu hiệu về mức độ hoạt động của mô hình trong các giai đoạn ở tương lai.
ps4_order = ps4_s.get_params()[‘order’]
ps4_seasorder = ps4_s.get_params()[‘seasonal_order’]
ps5_order = ps5_s.get_params()[‘order’]
ps5_seasorder = ps5_s.get_params()[‘seasonal_order’]
params = {
“ps4”: {“order”: ps4_order, “seasonal_order”: ps4_seasorder},
“ps5”: {“order”: ps5_order, “seasonal_order”: ps5_seasorder}
}
results = []
fig, axs = plt.subplots(len(X.columns), 1, figsize=(24, 12))
for i, col in enumerate(X.columns):
#Fit best model for each column
arima_model = SARIMAX(train_data[col],
order = params[col][“order”],
seasonal_order = params[col][“seasonal_order”])
arima_result = arima_model.fit()
#Predict
arima_pred = arima_result.predict(start = len(train_data),
end = len(X)-1, typ=”levels”)\
.rename(“ARIMA Predictions”)
#Plot predictions
test_data[col].plot(figsize = (8,4), legend=True, ax=axs[i])
arima_pred.plot(legend = True, ax=axs[i])
arima_rmse_error = rmse(test_data[col], arima_pred)
mean_value = X[col].mean()
results.append((col, arima_pred, arima_rmse_error, mean_value))
print(f’Column: {col} –> RMSE Error: {arima_rmse_error} – Mean: {mean_value}\n’)
Column: ps4 –> RMSE Error: 8.626764032898576 – Mean: 37.83461538461538
Column: ps5 –> RMSE Error: 27.552818032476257 – Mean: 3.973076923076923
Các dự báo cho thấy, các mô hình hoạt động tương đối tốt khi có đủ dữ liệu lịch sử cho tới khi diễn ra sự thay đổi đột ngột này, như chúng ta đã có cho “PS4” kể từ tháng 3 trở đi.
Còn đối với PS5, các mô hình hầu như không có gì ngay từ ban đầu.
Được biết, điều này xảy ra vì lỗi bình phương gốc (RMSE) là 8,62 đối với PS4, cao hơn một phần ba so với RMSE của PS5 là 27,5. Giả sử rằng Google Trends thay đổi từ 0 tới 100 thì đây là mức sai số khoảng 27%.
Dự báo tương lai
Tại thời điểm này, chúng ta sẽ thực hiện một công việc có thể nói là “khó tin” nhằm dự báo tương lai dựa trên các dữ liệu mà chúng ta đã có:
oos_train_data = ps_unstacked
oos_train_data.tail ()
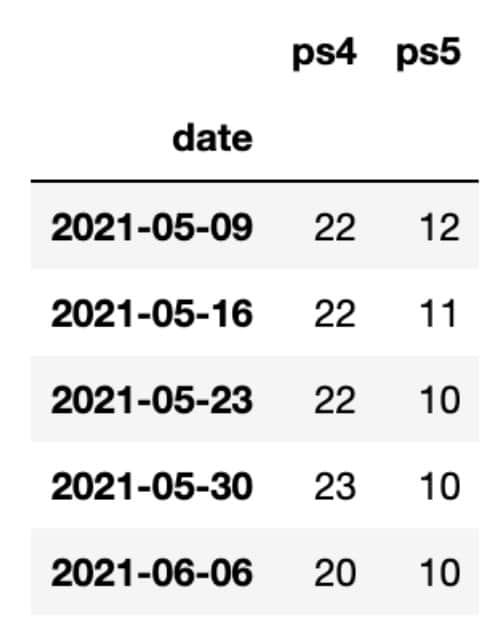
Như bạn có thể nhìn thấy từ bảng trích xuất ở trên, hiện đang được sử dụng tất cả các dữ liệu có sẵn.
Bây giờ, chúng ta sẽ dự đoán rằng trong 6 tháng tới (ở đây định nghĩa là 26 tuần) trong đoạn mã bên dưới đây:
oos_results = []
weeks_to_predict = 26
fig, axs = plt.subplots(len(ps_unstacked.columns), 1, figsize=(24, 12))
for i, col in enumerate(ps_unstacked.columns):
#Fit best model for each column
s = auto_arima(oos_train_data[col], trace=True)
oos_arima_model = SARIMAX(oos_train_data[col],
order = s.get_params()[‘order’],
seasonal_order = s.get_params()[‘seasonal_order’])
oos_arima_result = oos_arima_model.fit()
và
#Predict
oos_arima_pred = oos_arima_result.predict(start = len(oos_train_data),
end = len(oos_train_data) + weeks_to_predict, typ=”levels”).rename(“ARIMA Predictions”)
#Plot predictions
oos_arima_pred.plot(legend = True, ax=axs[i])
axs[i].legend([col]);
mean_value = ps_unstacked[col].mean()
oos_results.append((col, oos_arima_pred, mean_value))
print(f’Column: {col} – Mean: {mean_value}\n’)
Đầu ra:
Performing stepwise search to minimize aic
ARIMA(2,0,2)(0,0,0)[0] intercept : AIC=1829.734, Time=0.21 sec
ARIMA(0,0,0)(0,0,0)[0] intercept : AIC=1999.661, Time=0.01 sec
…
ARIMA(1,0,0)(0,0,0)[0] : AIC=1865.936, Time=0.02 sec
Best model: ARIMA(1,0,0)(0,0,0)[0] intercept
Total fit time: 0.722 seconds
Column: ps4 – Mean: 37.83461538461538
và
Performing stepwise search to minimize aic
ARIMA(2,1,2)(0,0,0)[0] intercept : AIC=1657.990, Time=0.19 sec
ARIMA(0,1,0)(0,0,0)[0] intercept : AIC=1696.958, Time=0.01 sec
…
ARIMA(4,1,4)(0,0,0)[0] : AIC=1645.756, Time=0.56 sec
Best model: ARIMA(3,1,3)(0,0,0)[0]
Total fit time: 7.954 seconds
Column: ps5 – Mean: 3.973076923076923
Lần này, tôi đã tự động hóa việc tìm kiếm các thông số phù hợp nhất và đưa trực tiếp thông số đó vào trong mô hình.
Dữ liệu đã có rất nhiều thay đổi trong vài tuần qua. Mặc dù, các xu hướng được dự báo trông có vẻ là sẽ có khả năng xảy ra, nhưng cảm giác không được chính xác cho lắm, các bạn có thể xem hiển thị ở phía bên dưới:
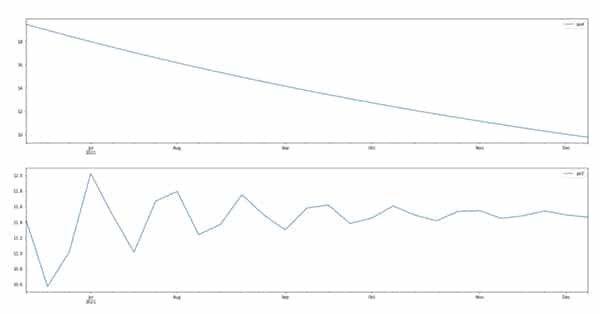
Đây là trong trường hợp của hai từ khóa đó, nếu bạn thực hiện đoạn mã trên dữ liệu khác của mình cùng các truy vấn đã được thiết lập nhiều hơn, chúng có thể sẽ cung cấp các dự báo chính xác hơn về dữ liệu của chính bạn.
Chất lượng dự báo sẽ phụ thuộc vào mức độ ổn định của các dữ liệu lịch sử và rõ ràng sẽ không tính tới các sự kiện không thể lường trước được như COVID-19.
Bắt đầu dự báo cho SEO
Nếu bạn cảm thấy không hứng thú với công cụ trực quan hóa dữ liệu matplot của Python thì cũng đừng lo. Bạn có thể xuất dữ liệu và dự báo sang Excel, Tableau hoặc giao diện bảng điều khiển khác để làm cho chúng trông được đẹp hơn.
Đề xuất dự báo của bạn:
df_pred = pd.concat([pd.Series(res[1]) for res in oos_results], axis=1)
df_pred.columns = [x + str(‘_preds’) for x in ps_unstacked.columns]
df_pred.to_csv(‘your_forecast_data.csv’)
Tất cả những gì mà chúng ta đã được học ở đây là dự báo bằng cách sử dụng các mô hình thống kê hữu ích hoặc có khả năng tăng thêm giá trị cho dự báo. Đặc biệt là trong các hệ thống tự động như trang tổng quan – tức là khi có dữ liệu lịch sử chứ không phải khi có đột biến giống như PS5.
