
Chỉ một ký tự sai trong tệp Robots.txt cũng có thể khiến toàn bộ website của bạn “vô hình” với Google. Dù đây là tệp cấu hình đơn giản, nhưng lại dễ gây hiểu nhầm và ảnh hưởng nghiêm trọng đến SEO nếu sử dụng sai. Trong bài viết này, bạn sẽ hiểu rõ robots.txt là gì, cách tạo, kiểm tra, tối ưu tệp này sao cho an toàn và hiệu quả với công cụ tìm kiếm.
Robots.txt là gì?

Robots.txt là một tệp văn bản được đọc bởi các công cụ tìm kiếm (ví dụ như Google, Bing và Yahoo), hay còn được gọi với cái tên “Robots Exclusion Protocol”, là kết quả của sự đồng thuận giữa các nhà phát triển công cụ tìm kiếm ban đầu.
Đây không phải là tiêu chuẩn chính thức do bất kỳ tổ chức tiêu chuẩn nào đặt ra; mặc dù là tất cả các công cụ tìm kiếm đều tuân theo nó.
Robots.txt sẽ thực hiện công việc gì?
Tôi sẽ nêu ra hai công việc chính của công cụ tìm kiếm để các bạn có được cái nhìn khái quát nhất:
- Thu thập thông tin trên website để bắt đầu việc ‘khám phá nội dung’ bên trong đó.
- Lập chỉ mục nội dung hay còn gọi là index nội dung để nó có thể cung cấp cho những người tìm kiếm đang đi tìm kiếm thông tin.
Để có thể thu thập dữ liệu các trang web, các công cụ tìm kiếm sẽ đi theo các liên kết để di chuyển từ trang này sang trang khác và cuối cùng chính là thu thập lại toàn bộ thông tin qua hàng tỷ liên kết khác và trang web khác nhau. Hành động thu thập thông tin này còn được gọi với cái tên “spidering”.
Sau khi đã tới được một trang web, trước khi bắt đầu việc xem xét trang web đó, trình thu thập thông tin (search crawler) sẽ tìm kiếm tệp Robots.txt.
Khi tìm thấy một tệp thì trình thu thập sẽ đọc tệp đó trước khi tiếp tục công việc của mình qua những trang kế tiếp. Lý do là bởi tệp robots.txt chứa thông tin về cách mà công cụ tìm kiếm sẽ thu thập thông tin, thông tin được tìm thấy ở đó sẽ hướng dẫn cho trình thu thập thông tin hành động tiếp theo trên trang web cụ thể này.
Nếu như tệp robots.txt không chứa bất kỳ lệnh nào không cho phép hoạt động của tác nhân người dùng (hay trang web đó không có tệp robots.txt) thì nó sẽ tiến hành việc thu thập thông tin ở trên những trang khác trên trang web.
Tại sao Robots.txt lại quan trọng?
Có thể nói rằng, hầu hết các trang web không cần tới tệp Robots.txt.
Lý do là bởi Google thường có thể tìm và lập chỉ mục tất cả các trang quan trọng trên trang web của bạn.
Tuy nhiên, họ sẽ KHÔNG lập chỉ mục các trang quan trọng hay các phiên bản trùng lặp của các trang khác.
Điều đó có thể diễn giải rằng, có 3 lý do chính mà bạn thực sự MUỐN sử dụng Robots.txt.
Chặn các trang không công khai
Đôi khi bạn có các trang trên trang web của mình mà bạn không muốn nó được lập chỉ mục.
Ví dụ: Bạn có thể có phiên bản theo từng giai đoạn của một trang hoặc một trang đăng nhập. Các trang này cần phải tồn tại. Nhưng bạn không muốn những người dùng ‘ngẫu nhiên đổ bộ’ vào chúng. Đây chính là trường hợp mà bạn sử dụng robots.txt để chặn các trang này ra khỏi trình thu thập thông tin và chương trình của công cụ tìm kiếm.
Tối đa hóa ngân sách thu thập thông tin
Nếu bạn gặp khó khăn trong việc lập chỉ mục tất cả các trang của mình, bạn có thể gặp vấn đề về ngân sách thu thập thông tin (Crawl Budget). Bằng cách chặn các trang không quan trọng bằng robots.txt, Googlebot có thể ‘chi tiêu’ nhiều hơn ngân sách thu thập thông tin của bạn trên các trang thực sự quan trọng.
Ngăn lập chỉ mục tài nguyên:
Sử dụng chỉ thị meta có thể hoạt động giống như Robots.txt để ngăn các trang được lập chỉ mục. Tuy nhiên, chỉ thị meta không hoạt động tốt cho các tài nguyên đa phương tiện, như PDF và hình ảnh. Đây chính là lúc mà robots.txt được phát huy khả năng của mình.
Điểm mấu chốt ở chỗ, Robots.txt yêu cầu trình thu thập thông tin của công cụ tìm kiếm không thu thập từ dữ liệu các trang cụ thể trên trang web của bạn.
Bạn có thể kiểm tra xem bạn đã lập chỉ mục bao nhiêu trang trong Google Search Console.
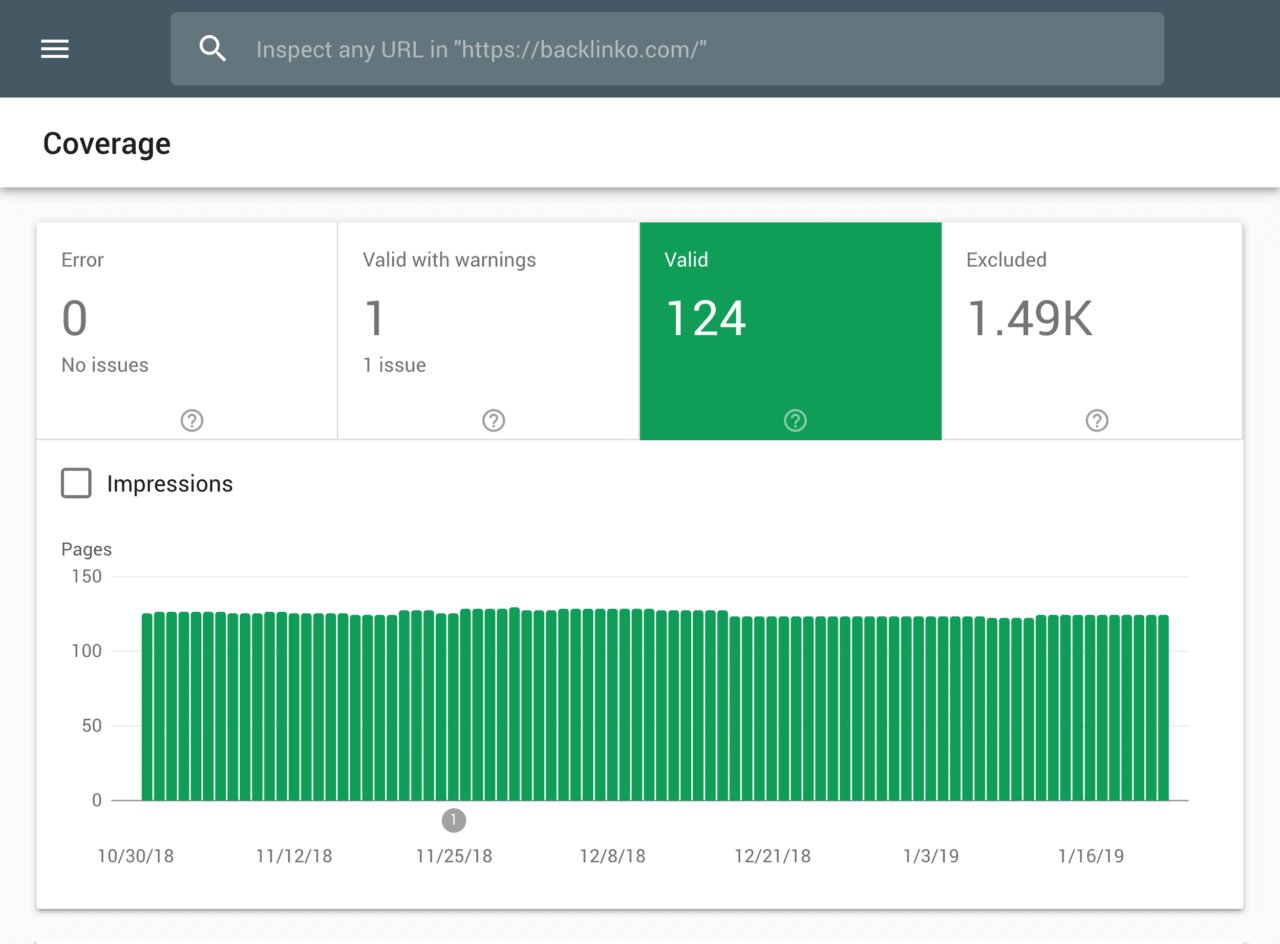
Nếu số đó khớp với số trang mà bạn muốn lập chỉ mục, bạn không cần bận tâm tới tệp Robots.txt.
Nhưng nếu con số đó cao hơn con số mà bạn mong đợi (và bạn nhận thấy các URL được lập chỉ mục không nên được lập chỉ mục), thì đã tới lúc tạo tệp robots.txt cho trang web của bạn.
Cách tạo tệp robots.txt
Nếu bạn chưa có tệp robots.txt, việc tạo ra một tệp rất dễ dàng. Chỉ cần mở một tài liệu .txt trống và bắt đầu nhập lệnh. Ví dụ: nếu bạn muốn không cho phép tất cả các công cụ tìm kiếm thu thập thông tin /admin/ folder của bạn, nó sẽ trông như sau:
User-agent: *
Disallow: /admin/
Tiếp tục xây dựng các chỉ thị cho đến khi bạn cảm thấy hài lòng với những gì mình có. Lưu tệp của bạn dưới dạng “robots.txt”.
Ngoài ra, bạn cũng có thể sử dụng trình tạo robots.txt như trình tạo này.
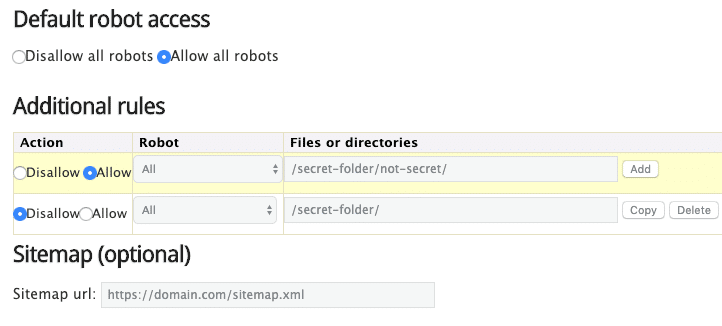
Ưu điểm của việc sử dụng một công cụ như thế này là nó giảm thiểu các lỗi cú pháp. Điều đó là tốt vì một sai lầm có thể dẫn tới ‘thảm họa’ trong SEO trên trang web của bạn – vì vậy, nếu sai sót ở khía cạnh này, có thể bạn sẽ phải mất tiền để bù đắp lại ‘sai lầm’ đó.
Điểm bất lợi là chúng hơi hạn chế về khả năng tùy chỉnh.
Nơi đặt tệp robots.txt của bạn
Đặt tệp robots.txt vào thư mục gốc của tên miền phụ mà nó áp dụng.
Ví dụ: để kiểm soát hành vi thu thập thông tin trên domain.com, tệp robots.txt phải truy cập được tại domain.com/robots.txt.
Nếu bạn muốn kiểm soát việc thu thập thông tin trên một miền phụ như blog.domain.com, thì tệp robots.txt phải truy cập được tại blog.domain.com/robots.txt.
Các phương pháp hay nhất về Robots.txt
Bạn hãy ghi nhớ về điều này để tránh khỏi những sai lầm thường gặp.
Sử dụng một dòng mới cho mỗi chỉ thị
Mỗi chỉ thị nên được nằm trên một dòng mới. Nếu không, có thể nó sẽ gây ra sự nhầm lần đối với các công cụ tìm kiếm.
Bad:
User-agent: * Disallow: /directory/ Disallow: /another-directory/
Good:
User-agent: *
Disallow: /directory/
Disallow: /another-directory/
Sử dụng các ký tự đại diện để đơn giản hóa hướng dẫn
Bạn không chỉ có thể sử dụng ký tự đại diện (*) để áp dụng lệnh đối với tất cả user-agents mà còn để khớp với các mẫu URL khi thực hiện khai báo lệnh.
Ví dụ: nếu bạn muốn ngăn công cụ tìm kiếm truy cập vào URL danh mục sản phẩm được tham số hóa trên trang web của mình, bạn có thể liệt kê chúng ra như sau:
User-agent: *
Disallow: /products/t-shirts?
Disallow: /products/hoodies?
Disallow: /products/jackets?
…
Nhưng tôi cho rằng điều đó không hiệu quả lắm. Sẽ tốt hơn nếu bạn đơn giản hóa mọi thứ bằng một ký tự đại diện như thế này:
User-agent: *
Disallow: /products/*?
Ví dụ này sẽ chặn các công cụ tìm kiếm thu thập thông tin tất cả các URL trong subfolder / product / có chứa dấu chấm hỏi.
Nói theo cách khác, bất kỳ URL danh mục sản phẩm được tham số hóa.
Sử dụng “$” để chỉ định phần cuối của một URL
Bao gồm biểu tượng “$” nhằm để đánh dấu phần cuối của một URL. Ví dụ: nếu bạn muốn ngăn các công cụ tìm kiếm truy cập vào tất cả các tệp .pdf trên trang web của mình, tệp robots.txt của bạn có thể sẽ trông giống như sau:
User-agent: *
Disallow: /*.pdf$
Trong ví dụ này, công cụ tìm kiếm không thể truy cập bất kỳ URL nào kết thúc bằng .pdf.
Điều đó có nghĩa là họ không thể truy cập vào /file.pdf, nhưng họ có thể truy cập /file.pdf?id=68937586 vì nó không được kết thúc bằng “.pdf” .
Chỉ sử dụng mỗi User-agent một lần
Nếu bạn chỉ định dùng cùng một user-agent nhiều lần, Google sẽ không bận tâm về điều đó. Nó sẽ chỉ kết hợp tất cả các quy tắc từ khai báo khác nhau thành một và tuân theo tất cả.
Ví dụ: nếu bạn có các chỉ thị và user-agent sau trong tệp robots.txt của mình…
User-agent: Googlebot
Disallow: /a/
User-agent: Googlebot
Disallow: /b/
Googlebot sẽ không thu thập thông tin một trong các thư mục đó.
Điều đó nói rằng, sẽ là hợp lý nếu chỉ khai báo mỗi user-agent một lần vì nó sẽ gây ít nhầm lẫn hơn. Nói cách khác, bạn sẽ ít mắc phải những sai lầm nghiêm trọng hơn bằng cách giữ mọi thứ gọn gàng và đơn giản.
Sử dụng tính cụ thể để tránh khỏi các lỗi không cố ý
Việc không cung cấp hướng dẫn cụ thể khi thiết lập chỉ thị có thể dẫn tới những sai lầm dễ bỏ sót và gây ra ảnh hưởng nghiêm trọng đến SEO.
Ví dụ: Giả sử rằng bạn có một trang web đa ngôn ngữ và bạn đang làm việc trên một phiên bản bằng tiếng Đức sẽ có sẵn trong thư mục con / de /.
Bởi vì nó chưa sẵn sàng hoạt động, bạn muốn ngăn các công cụ tìm kiếm truy cập vào nó.
Tệp robots.txt bên dưới sẽ ngăn các công cụ tìm kiếm truy cập vào thư mục con đó và mọi thứ trong đó:
User-agent: *
Disallow: /de
Nhưng nó cũng sẽ ngăn các công cụ tìm kiếm thu thập thông tin của bất kỳ trang hay tệp nào được bắt đầu bằng /de.
Ví dụ:
/designer-dresses/
/delivery-information.html
/depeche-mode/t-shirts/
/definitely-not-for-public-viewing.pdf
Trong trường hợp này, giải pháp sẽ rất đơn giản, chỉ cần thêm vào một dấu gạch chéo.
User-agent: *
Disallow: /de/
Sử dụng nhận xét để giải thích tệp robots.txt của bạn với con người
Nhận xét giúp giải thích robots.txt của bạn cho các nhà phát triển – và thậm chí có thể là chính bạn trong tương lai. Để bao gồm nhận xét, hãy bắt đầu dòng bằng dấu thăng (#).
# This instructs Bing not to crawl our site.
User-agent: Bingbot
Disallow: /
Trình thu thập thông tin sẽ bỏ qua mọi thứ ở trên các dòng bắt đầu bằng dấu (#).
Sử dụng tệp robots.txt riêng biệt cho từng Subdomain
Robots.txt chỉ kiểm soát hành vi thu thập thông tin trên miền phụ, nơi nó được lưu trữ. Nếu bạn muốn kiểm soát việc thu thập thông tin trên một miền phụ khác, bạn sẽ cần một tệp robots.txt riêng biệt.
Ví dụ: nếu trang web chính bạn nằm trên domain.com và blog của bạn nằm trên blog.domain.com, thì bạn sẽ cần hai tệp robots.txt. Một cái nên đi vào thư mục gốc của miền chính và cái kia trong thư mục gốc của blog.
Cách kiểm tra Robots.txt để tìm ra các vấn đề
Các lỗi của Robots.txt có thể lọt qua được khá dễ dàng, vì vậy bạn cần phải chú ý để theo dõi các vấn đề.
Để thực hiện công việc này, hãy thường xuyên kiểm tra các vấn đề liên quan tới robots.txt trong báo cáo “Coverage” trong Search Console. Dưới đây là một số lỗi bạn có thể gặp phải, ý nghĩa của chúng và cách mà bạn có thể sửa chúng.
Bạn cần kiểm tra các lỗi liên quan đến một trang nào đó?
Dán URL vào công cụ Kiểm tra URL của Google trong Search Console. Nếu nó bị chặn bởi robots.txt, bạn sẽ thấy một cái gì đó giống như sau:
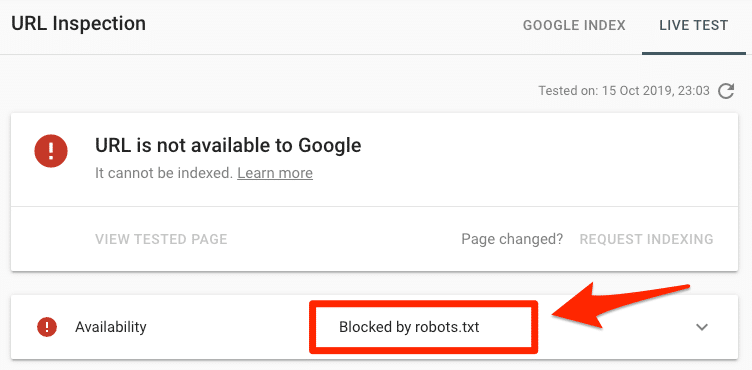
URL đã gửi bị chặn bởi robots.txt
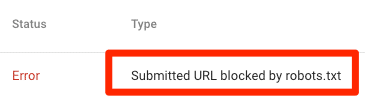
Điều này có nghĩa là ít nhất một trong các URL trong (các) sơ đồ trang web đã gửi của bạn đã bị robots.txt chặn.
Nếu bạn đã tạo sơ đồ trang web của mình một cách chính xác và loại trừ các trang được gắn canonical, không được lập chỉ mục và được redirect, thì không có trang nào được gửi sẽ bị robots.txt chặn. Nếu đúng như vậy, hãy kiểm tra xem trang nào đang bị ảnh hưởng, sau đó điều chỉnh tệp robots.txt của bạn sao cho phù hợp để xóa cho trang đó.
Bạn có thể sử dụng Google’s Robots.txt Tester để xem chỉ thị nào đang chặn nội dung. Chỉ cần cẩn thận khi thực hiện điều này. Rất dễ mắc lỗi ảnh hưởng đến các trang và tệp khác.
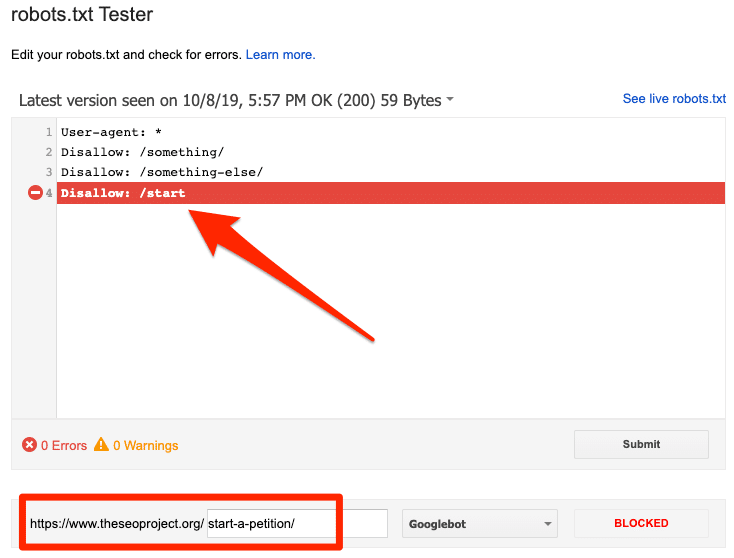
Bị chặn bởi robots.txt
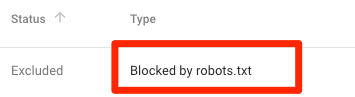
Điều này có nghĩa là bạn đang có nội dung bị chặn bởi robots.txt hiện không được lập chỉ mục trong Google.
Nếu nội dung này quan trọng và cần được lập chỉ mục, hãy xóa khối thu thập thông tin trong robots.txt. (Cũng cần đảm bảo rằng nội dung không được lập chỉ mục).
Nếu bạn đã chặn nội dung trong robots.txt với ý định loại trừ nội dung đó khỏi chỉ mục của Google, hãy xóa khối thu thập thông tin và thay vào đó sử dụng Meta Robots Tag hoặc X-Robots Title. Đó là cách duy nhất để đảm bảo loại trừ nội dung ra khỏi chỉ mục của Google.
Chú thích: Việc loại bỏ khối thu thập thông tin khi cố gắng loại trừ một trang ra khỏi kết quả tìm kiếm là rất quan trọng. Nếu không thực hiện được điều này và Google sẽ không nhìn thấy thẻ noindex hoặc Title HTTP – vì vậy, nó sẽ vẫn được lập chỉ mục.
Đã lập chỉ mục, mặc dù bị chặn bởi robots.txt
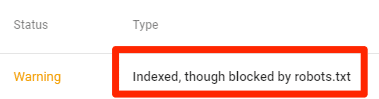
Điều này có nghĩa là một số nội dung đã bị robots.txt chặn vẫn được lập chỉ mục trong Google.
Một lần nữa, nếu bạn đang cố gắng loại trừ nội dung này ra khỏi kết quả tìm kiếm của Google, thì robots.txt không phải là giải pháp chính xác. Xóa khối thu thập thông tin và thay vào đó sử dụng Meta Robots Tag hoặc Title HTTp X-Robots để ngăn lập chỉ mục.
Nếu bạn vô tình chặn nội dung này và muốn giữ nó trong chỉ mục của Google, hãy xóa khối thu thập thông tin trong robots.txt. Điều này có thể giúp bạn cải thiện khả năng hiển thị của nội dung ở trong tìm kiếm của Google.
Đề xuất xem thêm bài: Khắc phục lỗi “Đã chặn bởi robots.txt vẫn bị lập chỉ mục” trong GSC
Robots.txt tuy nhỏ nhưng lại có sức ảnh hưởng lớn đến khả năng index và thứ hạng SEO của website. Hãy luôn kiểm tra kỹ cú pháp, đường dẫn và đừng quên test bằng công cụ của Google trước khi áp dụng. Một sai sót nhỏ cũng có thể khiến nội dung quan trọng của bạn biến mất khỏi kết quả tìm kiếm.
Nếu bạn mới bắt đầu học SEO, đừng bỏ qua những kiến thức kỹ thuật nền tảng khác như cấu trúc URL, sitemap.xml, hay Schema Markup. Tất cả đều góp phần giúp Google hiểu và đánh giá cao website của bạn hơn.
Bài viết được tham khảo từ: Ahrefs, Yoast, VietMoz, Backlinko, Moz.
Bản quyền thuộc về Đào tạo SEO VietMoz
Vui lòng không copy khi chưa được sự đồng ý của tác giả
