
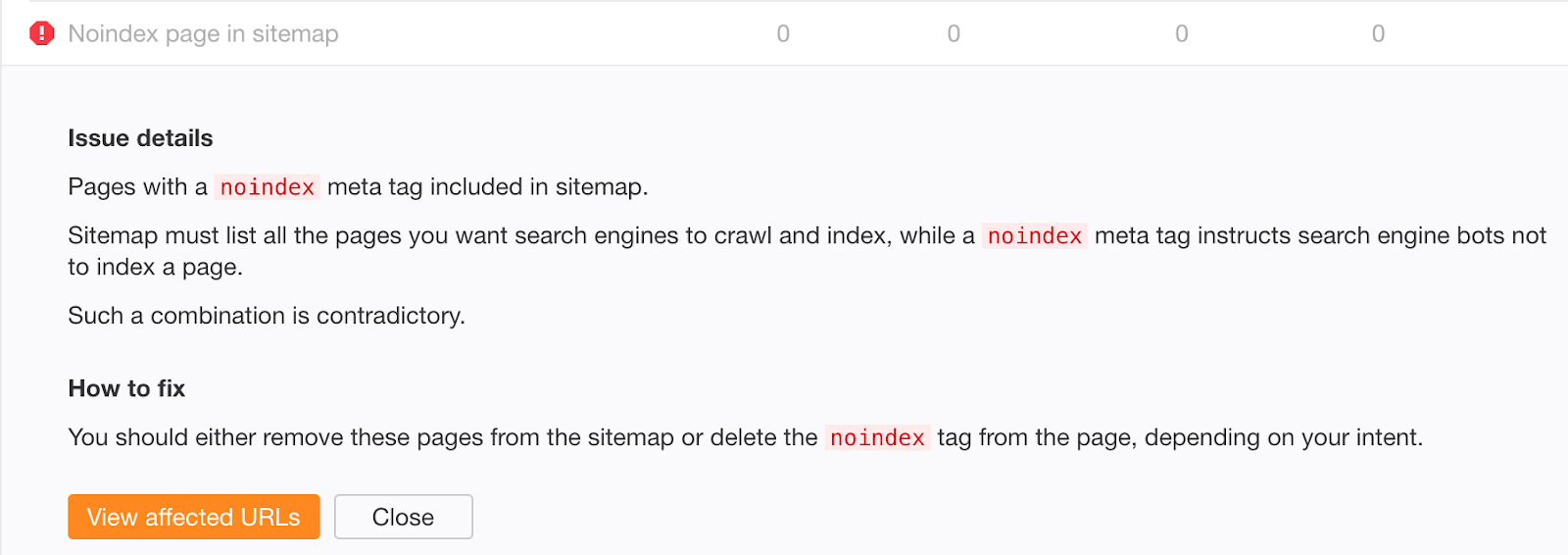
Robots Meta Tag là gì? Có một số nội dung trên trang web của bạn không cần thiết để các công cụ tìm kiếm lập chỉ mục. Để ngăn lập chỉ mục các trang đó, bạn có thể sử dụng Robots Meta Tag hoặc X-Robots-Tag.
Tuy nhiên, không có gì là lạ khi robots.txt và robots meta tag được sử dụng không chính xác. Điều này dẫn đến các chỉ thị lộn xộn và xung đột không đạt được kết quả như mong muốn: ngăn một trang được lập chỉ mục.
Và trong bài viết này, tôi muốn giúp bạn hiểu được cách sử dụng Robots Meta Tag và X-Robots-Tag để kiểm soát việc lập chỉ mục nội dung trang web của bạn và giúp bạn phát hiện những lỗi thường mắc phải.
Robots Meta Tags là gì?
Robots Meta Tags hay còn được gọi là Robots Tags, là một đoạn mã HTML được đặt trong phần <head> </head> của trang web và được sử dụng để kiểm soát cách công cụ tìm kiếm thu thập thông tin và lập chỉ mục URL.
Robots Meta Tags sẽ trông như thế này trong mã nguồn của một trang:
<meta name=”robots” content=”noindex” />
Cách thẻ này dành riêng cho từng trang và cho phép bạn hướng dẫn các công cụ tìm kiếm về cách bạn muốn chúng xử lý trang và có đưa nó vào chỉ mục hay không.
Robots Meta Tags được sử dụng để làm gì?
Robots meta tags được sử dụng để kiểm soát cách Google lập chỉ mục nội dung trang web của bạn. Điều này bao gồm:
- Có đưa một trang vào kết quả tìm kiếm hay không?
- Có theo dõi các liên kết trên một trang hay không (ngay cả khi nó bị chặn lập chỉ mục)
- Yêu cầu không lập chỉ mục các hình ảnh trên một trang
- Yêu cầu không hiển thị kết quả được lưu trong bộ nhớ cache của trang web trên SERPs.
- Yêu cầu không hiển thị một đoạn mã (mô tả meta) cho trang trên SERPs.
Để hiểu cách bạn có thể sử dụng robots meta tags, chúng ta cần xem xét các thuộc tính và chỉ thị khác nhau. Tôi cũng sẽ chia sẻ các ví dụ mã mà bạn có thể lấy và thả vào tiêu đề trang của mình để yêu cầu các công cụ tìm kiếm lập chỉ mục trang của bạn theo một cách nhất định.
Tại sao Robots Meta Tags lại quan trọng đối với SEO?
Robots Meta Tags thường được sử dụng để ngăn các trang hiển thị trong kết quả tìm kiếm, mặc dù thẻ này có các mục đích sử dụng khác (nhiều hơn về sau).
Có nhiều loại nội dung khác nhau mà bạn có thể muốn ngăn các công cụ tìm kiếm lập chỉ mục:
- Các trang mỏng có ít hoặc không có giá trị cho người dùng;
- Các trang trong môi trường ‘thử nghiệm’, dàn dựng;
- Trang quản trị và cảm ơn;
- Kết quả tìm kiếm nội bộ;
- Các trang đích của PPC;
- Các trang về các chương trình khuyến mãi, cuộc thi hoặc giới thiệu sản phẩm sắp tới;
- Nội dung trùng lặp – Duplicate Content (sử dụng Canonical Tags để đề xuất phiên bản tốt nhất cho việc lập chỉ mục);
Nói chung, trang web của bạn càng lớn, bạn càng phải xử lý nhiều hơn việc quản lý khả năng thu thập dữ liệu và lập chỉ mục. Bạn cũng muốn Google và các công cụ tìm kiếm khác thu thập thông tin và lập chỉ mục các trang của bạn một cách hiệu quả nhất có thể.
Cho nên, việc kết hợp chính xác các chỉ thị cấp trang với robots.txt và sơ đồ trang web (sitemap) là rất quan trọng đối với SEO.
Các giá trị và thuộc tính của Robots Meta Tags là gì?
Robots meta tag bao gồm hai thuộc tính: name và content.
Bạn bắt buộc phải chỉ định các giá trị cho từng thuộc tính này. Hãy cùng tôi khám phá đây là những gì.
Thuộc tính name và các giá trị tác nhân người dùng
Thuộc tính name chỉ định trình thu thập thông tin nào phải tuân theo các hướng dẫn này. Giá trị này còn được gọi là tác nhân người dùng (User-agent hay UA) vì trình thu thập thông tin cần được xác định với UA của chúng để yêu cầu trang. UA của bạn phản ánh trình duyệt bạn đang sử dụng, nhưng các user-agent của Google, chẳng hạn như Googlebot hoặc Googlebot-image.
Giá trị UA “robots” áp dụng cho tất cả các trình thu thập thông tin. Bạn cũng có thể thêm bao nhiêu robots meta tags vào phần <head> nếu cần.
Ví dụ: nếu bạn muốn ngăn hình ảnh của mình hiển thị trong tìm kiếm hình ảnh trên Google hoặc Bing, hãy thêm các thẻ meta sau:
<meta name=”googlebot-image” content=”noindex” />
<meta name=”MSNBot-Media” content=”noindex” />
Chú thích: Cả hai thuộc tính trên và nội dung đều không phân biệt chữ hoa chữ thường. Các thuộc tính “Googlebot-Image”,”msnbot-media” và “Noindex” cũng hoạt động cho các ví dụ trên.
Thuộc tính Content và chỉ thị thu thập thông tin / lập chỉ mục
Thuộc tính content cung cấp hướng dẫn về cách thu thập thông tin và lập chỉ mục thông tin trên trang. nếu không có sẵn Robots meta tag, trình thu thập thông tin sẽ hiểu nó là chỉ mục và theo dõi.
Điều đó cho phép họ hiển thị trang trong kết quả tìm kiếm và thu thập thông tin tất cả các liên kết trên trang (trừ khi có quy định khác với thẻ rel=”nofollow”).
Sau đây là các giá trị được Google hỗ trợ cho thuộc tính content:
All ( Tất cả)
Giá trị mặc định của “index, follow”, không cần sử dụng chỉ thị này.
<meta name=”robots” content=”all” />
Noindex
Hướng dẫn các công cụ tìm kiếm không lập chỉ mục trang. Điều đó ngăn không cho nó hiển thị trong kết quả tìm kiếm.
<meta name=”robots” content=”noindex” />
Nofollow
Ngăn không cho robots thu thập thông tin tất cả các liên kết trên trang. Xin lưu ý rằng những URL đó vẫn có thể được lập chỉ mục, đặc biệt nếu chúng có liên kết ngược (backlink) trỏ đến.
<meta name=”robots” content=”nofollow” />
None
Sự kết hợp của noindex, nofollow. Trành sử dụng lệnh này vì các công cụ tìm kiếm khác (ví dụ: Bing) không hỗ trợ cho nó.
<meta name=”robots” content=”none” />
Noarchive
Ngăn Google hiển thị bản sao đã lưu trong bộ nhớ cache của trang trong SERP.
<meta name=”robots” content=”noarchive” />
Notranslate
Ngăn Google cung cấp bản dịch của trang trong SERP.
<meta name=”robots” content=”notranslate” />
noimageindex
Ngăn Google lập chỉ mục các hình ảnh được nhúng trên trang.
<meta name=”robots” content=”noimageindex” />
Yêu cầu Google không hiển thị một trang trong kết quả tìm kiếm sau một ngày / giờ cụ thể. Về cơ bản là một chỉ thị noindex với một bộ đếm thời gian. Ngày / giờ phải được chỉ định bằng định dạng RFC 850.
<meta name=”robots” content=”unavailable_after: Sunday, 01-Sep-19 12:34:56 GMT” />
nosnippet
Chọn không tham gia tất cả các đoạn văn bản và video trong SERP. Nó cũng hoạt động như noarchive cùng một lúc.
<meta name=”robots” content=”nosnippet” />
LƯU Ý QUAN TRỌNG
Kể từ tháng 10 năm 2019, Google cung cấp các tùy chọn chi tiết hơn để kiểm soát ‘if’ và cách bạn muốn hiển thị các đoạn trích của mình trong kết quả tìm kiếm. Điều này một phần là do Chỉ thị Bản quyền Châu Âu, lần đầu tiên được Pháp thực hiện với luật bản quyền mới.
Điều quan trọng, luật này đã ảnh hưởng đến tất cả các chủ sở hữu trang web. Tại sao? Bởi vì Google không còn hiển thị các đoạn trích (văn bản, hình ảnh hoặc video) từ trang web của bạn cho người dùng ở Pháp trừ khi bạn chọn tham gia bằng cách sử dụng Robots meta tag mới của họ.
Tôi sẽ thảo luận về cách hoạt động của từng thẻ mới này ở phía bên dưới. Điều đó có nghĩa là, nếu điều này liên quan đến doanh nghiệp của bạn và bạn đang tìm kiếm một giải pháp nhanh chóng, hãy thêm đoạn mã HTML sau vào mỗi trang trên trang web của bạn để cho Google biết rằng bạn không muốn có bất kỳ giới hạn nào đối với các đoạn mã của mình:
<meta name=”robots” content=”max-snippet:-1, max-image-preview:large, max-video-preview:-1″ />
Lưu ý rằng nếu bạn sử dụng Yoast SEO, đoạn mã này được thêm tự động trên mọi trang trừ khi bạn thêm chỉ định noindex hoặc nosnippet.
max-snippet:
Chỉ định số lượng ký tự tối đa mà Google có thể hiển thị trong các đoạn văn bản của họ. Sử dụng 0 sẽ chọn không tham gia các đoạn văn bản, -1 tuyên bố không có giới hạn về bản xem trước văn bản.
Thẻ sau sẽ thiết lập giới hạn 160 ký tự (tương tự như độ dài mô tả meta tiêu chuẩn):
<meta name=”robots” content=”max-snippet:160″ />
max-image-preview:
Cho Google biết liệu nó có thể sử dụng một hình ảnh lớn như thế nào cho các đoạn mã hình ảnh. Chỉ thị này có ba giá trị có thể có:
- Không có đoạn mã hình ảnh nào sẽ được hiển thị
- Tiêu chuẩn – bản xem trước hình ảnh mặc định có thể được hiển thị.
- Lớn – bản xem trước hình ảnh lớn nhất có thể được hiển thị.
<meta name=”robots” content=”max-image-preview:large” />
max-video-preview:
Thiết lập số giây tối đa cho một đoạn video. Như với đoạn văn bản, 0 sẽ chọn không hoàn toàn, -1 là không giới hạn.
Thẻ sau sẽ cho phép Google hiển thị tối đa 15 giây:
<meta name=”robots” content=”max-video-preview:15″ />
MỘT GHI CHÚ NHANH VỀ VIỆC SỬ DỤNG THUỘC TÍNH HTML data-nosnippet
Cùng với các chỉ thị robots mới được giới thiệu vào tháng 10 năm 2019, Google cũng đã giới thiệu thuộc tính HTML data-nosnippet. Bạn có thể sử dụng chúng để gắn thẻ các phần văn bản mà bạn không muốn Google sử dụng làm đoạn trích.
Điều này có thể được thực hiện trong HTML trên các phần tử div, span và section. Data-nosnippet được coi là một thuộc tính boolean, nghĩa là nó có hoặc không có giá trị.
<p>This is some text in a paragraph that can be shown as a snippet<span data-nosnippet>excluding this part</span></p>
<div data-nosnippet>This will not appear in a snippet</div><div data-nosnippet=”true”>And neither will this</div>
Sử dụng các chỉ thị này
Hầu hết những người làm SEO không cần phải vượt ra ngoài các chỉ thị noindex và nofollow, nhưng sẽ thật tốt khi biết rằng cũng có các tùy chọn khác. Hãy nhớ rằng tất cả các lệnh được liệt kê ở trên đều được Google hỗ trợ.
Hãy kiểm tra sự so sánh với Bing:
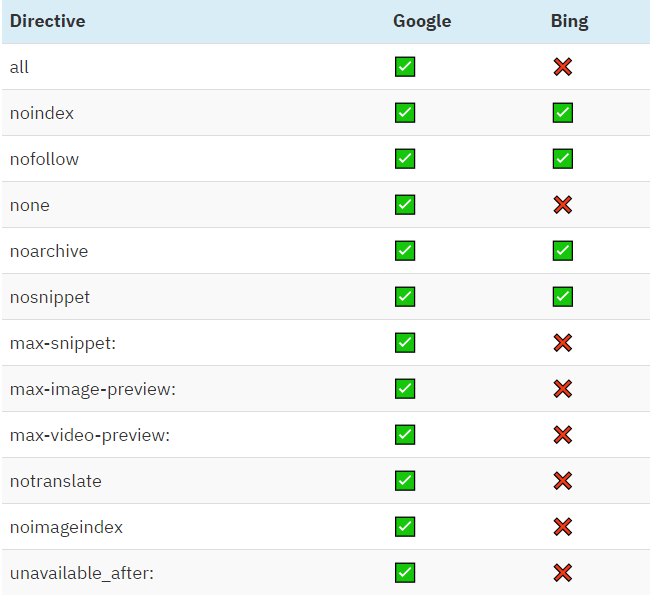
Bạn có thể sử dụng nhiều chỉ thị cùng một lúc và kết hợp chúng. Nhưng nếu chúng xung đột (ví dụ: “noindex,index”) hoặc một cái là tập hợp con của một cái khác (ví dụ: ”noindex, noarchive”), Google sẽ sử dụng một cái hạn chế nhật. Trong trường hợp này, nó chỉ là “noindex”.
Chú thích: Chỉ thị đoạn mã có thể bị ghi đè bởi structured data cho phép Google sử dụng bất kỳ thông tin nào trong chú thích. Nếu bạn muốn ngăn Google hiển thị các đoạn trích, hãy điều chỉnh chú thích cho phù hợp và đảm bảo rằng bạn không có bất kỳ thỏa thuận cấp phép nào đối với Google.
MỘT LƯU Ý VỀ CÁC CHỈ THỊ KHÁC
Bạn cũng có thể bắt gặp các chỉ thị dành riêng cho các công cụ tìm kiếm khác. Một ví dụ sẽ là “noyaca” ngăn Yandex sử dụng thư mục riêng của mình để tạo các đoạn kết quả tìm kiếm.
Những thứ khác có thể hữu ích và được sử dụng trong quá khứ nhưng giờ không còn được dùng nữa. Ví dụ: chỉ thị “preferp” được sử dụng để ngăn các công cụ tìm kiếm sử dụng Dự án Thư mục Mở để tạo các đoạn mã.
Cách thiết lập Robots Meta Tags
Giờ đây, bạn đã biết tất cả các lệnh này hoạt động và trông như thế nào, đã tới lúc triển khai thực tết trên trang web của bạn.
Robots meta tag thuộc về phần <head> của một trang. Sẽ khá đơn giản nếu bạn chỉnh sửa mã bằng trình chỉnh sửa HTML như Notepad ++ hoặc Brackets.
Tuy nhiên, điều gì sẽ xảy ra nếu bạn đang sử dụng CMS với các plugin SEO?
Hãy tập trung vào tùy chọn phổ biến nhất hiện có.
Chuyển đến phần “Advanced” bên dưới khối chỉnh sửa của mỗi bài đăng hoặc trang. Thiết lập robots meta tag theo nhu cầu của bạn. Các cài đặt sau sẽ triển khai các lệnh “noindex, nofollow”.
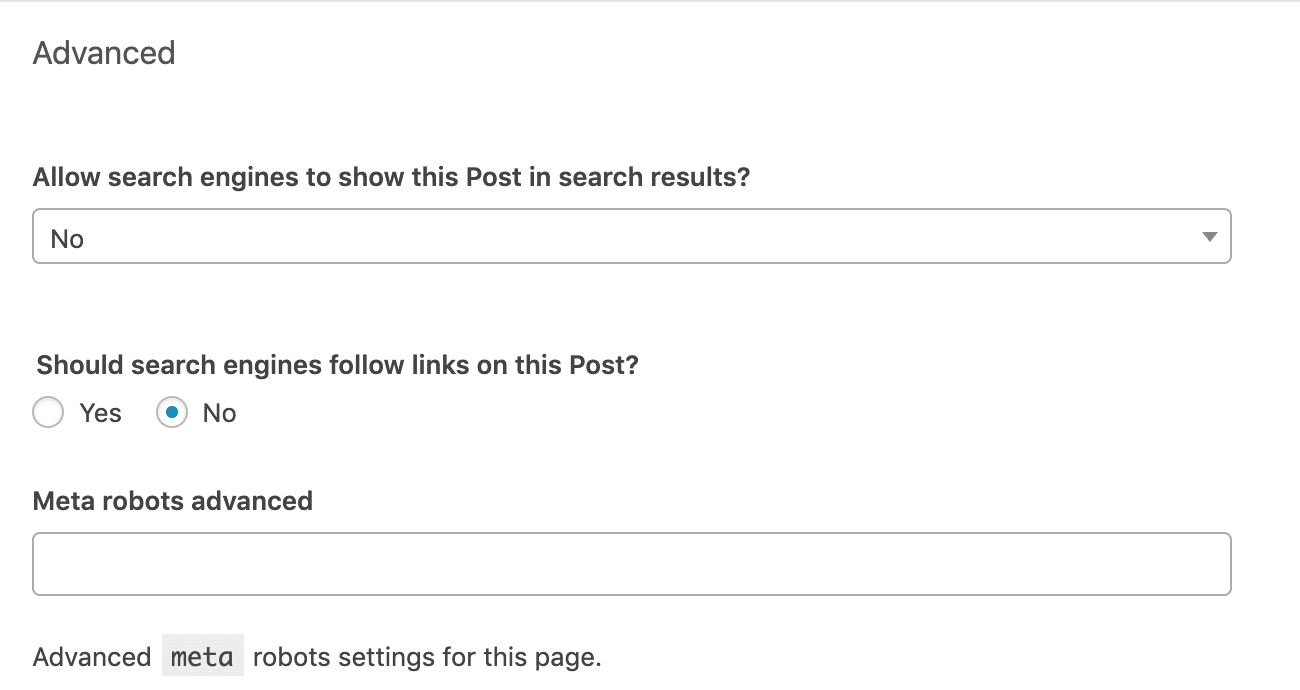
Phần “Meta robots advanced” cung cấp cho bạn tùy chọn triển khai các chỉ thị ngoài noindex và nofollow, chẳng hạn như noimageindex.
Bạn cũng có tùy chọn để áp dụng các chỉ thị này trên toàn trang web. Đi tới “Search Appearance” trong menu Yoast. Ở đó, bạn có thể thiết lập robots meta tag trên tất cả các bài đăng, trang hoặc chỉ trên các đơn vị phân loại hoặc lưu trữ cụ thể.
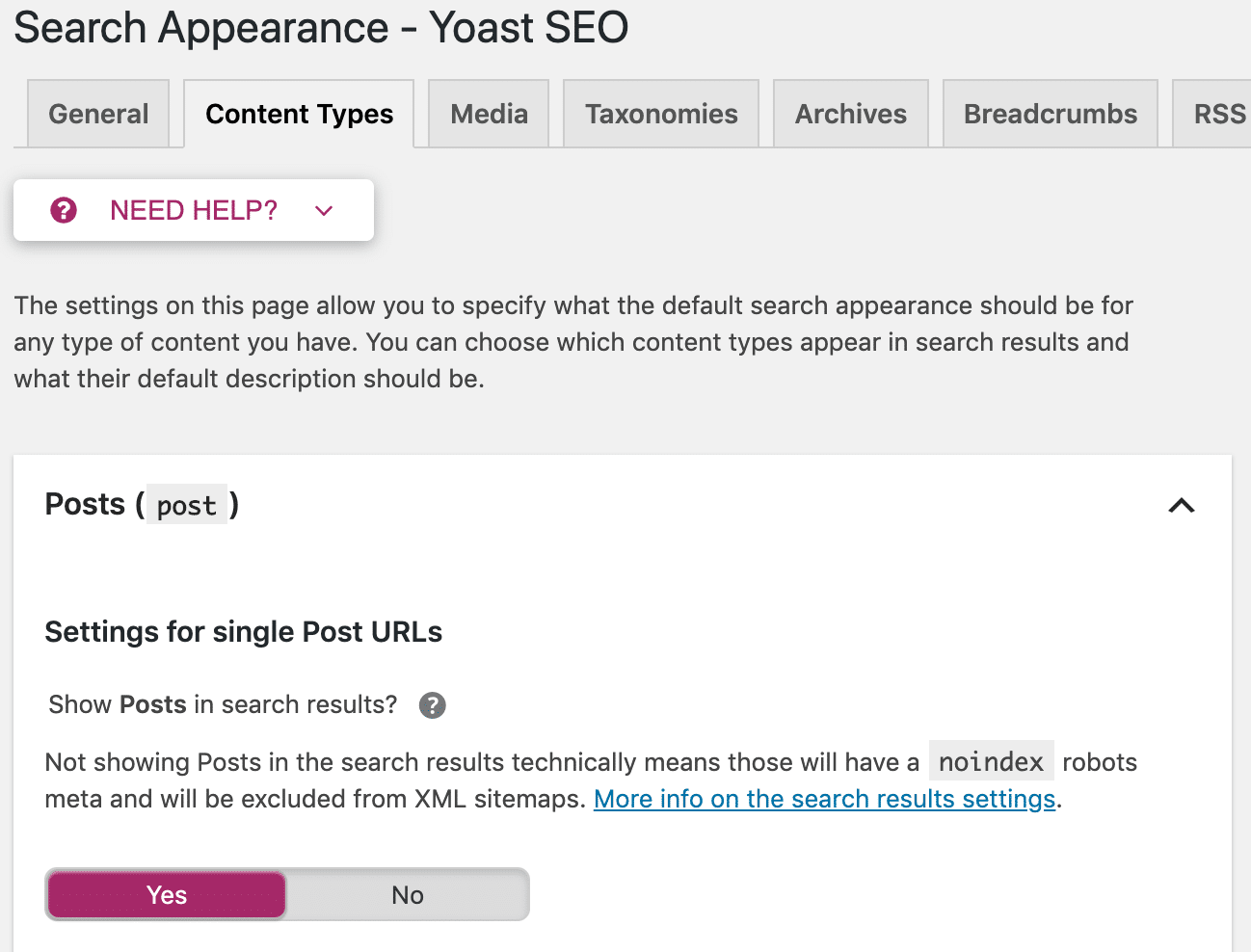
Chú thích: Yoast không phải là cách duy nhất để kiểm soát các robots meta tag trong WordPress. Có rất nhiều plugin SEO WordPress khác có chức năng tương tự.
X-Robots-Tag là gì?
Một cách thay thế để kiểm soát cách mà công cụ tìm kiếm thu thập dữ liệu và lập chỉ mục các trang web của bạn là sử dụng X-robots-tag thay vì robots meta tag.
Mặc dù việc triển khai robots meta tags cho các trang HTML tương đối đơn giản, tuy nhiên X-robots-tag lại phức tạp hơn. Nếu bạn muốn kiểm soát cách xử lý nội dung không phải HTML, chẳng hạn như PDF, bạn sẽ cần sử dụng x-robots-tag.
Đây là phản hồi tiêu đề HTTP, chứ không phải thẻ HTML và bất kỳ lệnh nào có thể được sử dụng làm robots meta tag cũng có thể được sử dụng làm x-robots-tag.
Dưới đây là ví dụ về phản hồi tiêu đề x-robots-tag trông như thế nào:
x-robots-tag: noindex, nofollow
Để sử dụng thẻ x-robots-tag, bạn cần truy cập vào tệp tin cấu hình máy chủ .php, .htaccess hoặc tệp cấu hình máy chủ của tiêu đề trang web của bạn. Nếu bạn không có quyền truy cập vào, bạn sẽ cần sử dụng robots meta tag để hướng dẫn trình thu thập thông tin.
Khi nào sử dụng X-Robots-Tag?
Sử dụng thẻ X-robots không đơn giản như sử dụng thẻ meta robots, nhưng cho phép bạn hướng các công cụ tìm kiếm cách lập chỉ mục và thu thập thông tin các loại tệp khác.
Sử dụng X-Robots-Tag khi:
- Bạn cần kiểm soát cách công cụ tìm kiếm thu thập thông tin và lập chỉ mục các loại tệp không phải HTML.
- Bạn cần cung cấp chỉ thị ở cấp độ toàn cầu (trang web) chứ không phải ở cấp độ trang.
Cách thiết lập X‑Robots-Tag
Cấu hình phụ thuộc vào loại máy chủ web bạn đang sử dụng và những trang hoặc tệp nào bạn muốn giữ ngoài chỉ mục.
Dòng mã sẽ trông như thế này:
Header set X-Robots-Tag “noindex”
Ví dụ này có tính đến loại máy chủ phổ biến nhất – Apache. Cách thực tế nhất để thêm tiêu đề HTTP là sửa đổi tệp cấu hình chính (thường là httpd.conf) hoặc tệp .htaccess. Đây là nơi mà redirect xảy ra.
Bạn sử dụng các giá trị và chỉ thị tương tự cho x-robots-tag làm robots meta tag. Điều đó nói rằng, việc thực hiện những thay đổi này nên được để cho những người có kinh nghiệm. Phần backup sẽ giống như một người bạn của bạn vì ngay cả một lỗi cú pháp nhỏ cũng có thể khiến toàn bộ trang web bị phá vỡ.
Mẹo: Nếu bạn sử dụng CDN hỗ trợ các ứng dụng không máy chủ cho Edge SEO, bạn có thể sửa đổi cả robots meta tag và X-robots-tags trên máy chủ mà không cần thực hiện thay đổi đối với cơ sở mã bên dưới.
Khi nào sử dụng Robots Meta Tags với X-Robots-Tag?
Mặc dù việc thêm đoạn mã HTMl có vẻ là tùy chọn dễ dàng và đơn giản nhất, nhưng nó lại không thành công trong một số trường hợp.
Tệp không phải HTML
Bạn không thể đặt đoạn mã HTML vào các tệp không phải HTML, chẳng hạn như PDF hoặc hình ảnh. X-robots-tag là cách duy nhất.
Đoạn mã sau (trên máy chủ Apache) sẽ định cấu hình tiêu đề HTTP noindex trên tất cả các tệp PDF trên trang web.
<Files ~ “\.pdf$”>
Header set X-Robots-Tag “noindex”
</Files>
Áp dụng các chỉ thị trên quy mô lớn
Nếu bạn cần ngăn lập chỉ mục toàn bộ tên miền (phụ) – subdomain và thư mục con (subfolder), các trang có tham số nhất định hoặc bất kỳ thứ gì khác yêu cầu chỉnh sửa hàng loạt, hãy sử dụng x-robots-tags. Vì nó dễ thực hiện hơn.
Các sửa đổi tiêu đề HTTP có thể được so khớp với URL và tên tệp bằng cách sử dụng biểu thức chính quy. Chỉnh sửa hàng loạt phức tạp trong HTML bằng cách sử dụng chức năng tìm kiếm và thay thế thường sẽ yêu cầu nhiều thời gian và khả năng tính toán hơn.
Lưu lượng truy cập từ các công cụ tìm kiếm không phải Google
Google hỗ trợ cả Robots meta tag và X-robots-tag, nhưng đây không phải là trường hợp của tất cả các công cụ tìm kiếm.
Ví dụ, Seznam, một công cụ tìm kiếm của CH Séc chỉ hỗ trợ các thẻ robots meta tag. Nếu bạn muốn kiểm soát cách công cụ tìm kiếm này thu thập dữ liệu và lập chỉ mục các trang của bạn, thì việc sử dụng các thẻ X-robots-tag sẽ không hoạt động. Bạn cần sử dụng các đoạn mã HTML.
Cách tránh các lỗi về khả năng thu thập thông tin và lập chỉ mục
Bạn muốn hiển thị tất cả các trang có giá trị, tránh nội dung trùng lặp, các vấn đề không để các trang cụ thể ra khỏi chỉ mục.
Neus bạn quản lý một trang web lớn thì quản lý ngân sách thu thập thông tin (Crawl Budget) là một điều khác cần phải chú ý.
Chúng ta hãy xem xét những sai lầm phổ biến nhất mà mọi người thường mắc phải liên quan đến lệnh robots.
Sai lầm #1: Thêm lệnh noindex vào các trang không được phép trong robots.txt
Không bao giờ cho phép noindex nội dung mà bạn đang cố gỡ chỉ mục trong robots.txt. Làm như vậy sẽ ngăn các công cụ tìm kiếm thu thập lại thông tin trang và phát hiện ra lệnh ngăn lập chỉ mục.
Nếu bạn cảm thấy mình có thể đã mắc phải lỗi đó trong quá khứ, hãy thu thập dữ liệu trang web của bạn bằng Site Audit. Tìm các trang có lỗi “Noindex page receives organic traffic”.
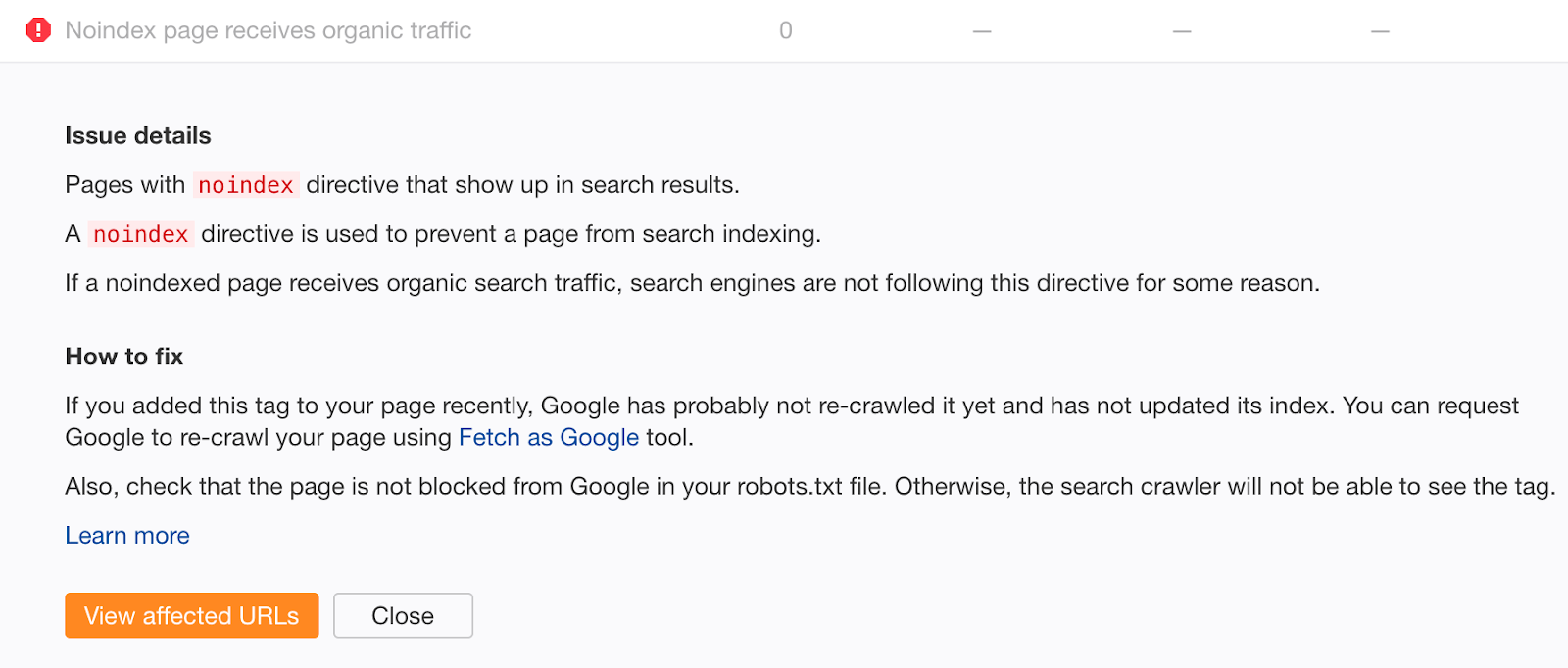
Các trang không lập chỉ mục nhận được lưu lượng truy cập không phải trả tiền rõ ràng vẫn được lập chỉ mục.
Nếu gần đây bạn không thêm thẻ noindex, rất có thể điều này là do khối thu thập thông tin trong tệp robots.txt của bạn. Kiểm tra các vấn đề và khắc phục chúng nếu thích hợp.
Sai lầm #2: Quản lý hồ sơ trang web không hợp lệ
Nếu bạn đang cố gắng đưa nội dung được lập chỉ mục bằng robots meta tag hoặc X-robots-tag, đừng xóa nội dung đó ra khỏi sitemap của bạn cho đến khi nó được khử chỉ mục thành công. Nếu không, Google có thể thu thập lại dữ liệu trang chậm hơn.
@methode Hello Sir.Just had a quick question. Does submitting an XML sitemap with urls marked as NOINDEX speed up the deindexation process?
— Nishanth Stephen (@nishanthstephen) October 13, 2015
Để có khả năng đẩy nhanh quá trình khử chỉ mục hơn nữa, hãy đặt ngày sửa đổi cuối cùng trong sitemap của bạn thành ngày bạn thêm thẻ ngăn lập chỉ mục. Điều này khuyến khích thu thập lại thông tin và xử lý lại.
Another trick you can do is submit a sitemap file with a lastmod date matching when you 404’d to encourage recrawl & reprocessing.
— ? John ? (@JohnMu) January 16, 2017
Chú thích: John đang nói về 404 ở đây. Điều đó thể hiện rằng, chúng tôi đã giả định rằng điều này cũng có ý nghĩa đối với các thay đổi khác khi bạn thêm hoặc xóa lệnh noindex.
Lưu ý quan trọng:
Không bao gồm các trang không được lập chỉ mục trong sitemap của bạn về lâu dài. Khi nội dung đã được lập chỉ mục, hãy xóa nội dung đó ra khỏi sitemap của bạn.
Nếu bạn lo lắng rằng nội dung cũ, được lập chỉ mục thành công vẫn có thể tồn tại trong sitemap của mình, hãy kiểm tra lỗi “Noindex page sitemap” trong Site Audit.
Sai lầm #3: Không xóa chỉ thị noindex khỏi môi trường dàn dựng (thử nghiệm)
Việc ngăn chặn robots thu thập dữ liệu và lập chỉ mục bất kỳ thứ gì trong môi trường dàn dựng (thử nghiệm) là một phương pháp hay. Tuy nhiên, đôi khi nó bị đẩy vào ‘thực tế’, bị lãng quên và Organic Traffic của bạn giảm xuống.
Thậm chí tệ hơn, sự sụt giảm lưu lượng truy cập không phải trả tiền (Organic Traffic) có thể không đáng chú ý nếu bạn tham gia vào quá trình di chuyển trang web bằng cách sử dụng chuyển hướng 301.
Nếu các URL mới chứa lệnh noindex hoặc không được phép trong robots.txt, bạn vẫn sẽ nhận được lưu lượng không phải trả tiền từ các URL cũ trong một thời gian. Google có thẻ mất đến vài tuần để khử chỉ mục các URL cũ.
Bất cứ khi nào có những thay đổi như vậy trên trang web của bạn, hãy theo dõi cảnh báo “Noindex page” trong site audit:
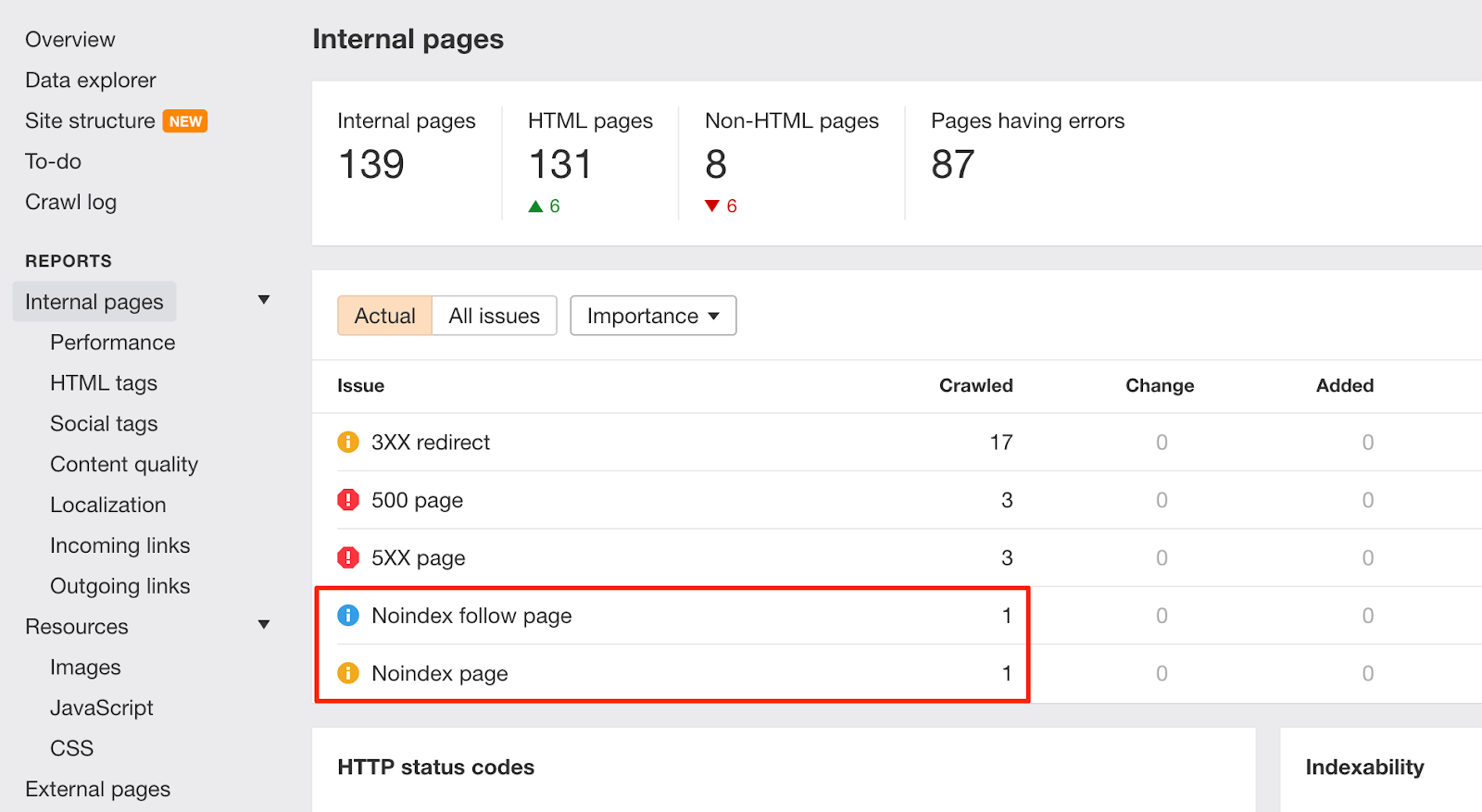
Để giúp ngăn chặn các vấn đề tương tự trong tương lai, hãy làm phong phú thêm danh sách kiểm tra của nhóm nhà phát triển với các hướng dẫn xóa quy tắc không cho phép khỏi robots.txt và lệnh noindex trước khi chuyển sang phiên bản ‘thực tế’.
Sai lầm #4: Thêm URL “bí mật” vào robots.txt thay vì ngăn lập chỉ mục chúng
Các nhà phát triển thường cố gắng ẩn các trang về các chương trình khuyến mãi, giảm giá hoặc ra mắt sản phẩm sắp tới bằng cách không cho phép truy cập vào chúng trong tệp robots.txt của trang web.
Đây là một thực tiễn không tốt vì con người vẫn có thể xem tệp robots.txt. Như vậy, các trang này rất dễ bị ‘rò rỉ’.
Khắc phục điều này bằng cách giữ các trang “bí mật” không sử dụng tệp robots.txt và thay vào, ngăn lập chỉ mục chúng.
Tóm lại
Hiểu đúng và quản lý việc thu thập thông tin và lập chỉ mục trang web của bạn là nền tảng của SEO. Technical SEO có thể khá phức tạp, tuy nhiên các thẻ robots meta thì không có gì phải sợ.
Hy vọng rằng bây giờ bạn đã sẵn sàng để áp dụng các phương pháp hay nhất cho các giải pháp lâu dài trên quy mô lớn.
Bài viết được tham khảo từ: Ahrefs, VietMoz, SEMRush .
Bản quyền thuộc về Đào tạo SEO VietMoz
Vui lòng không copy khi chưa được sự đồng ý của tác giả
