
Với nhiều người mới bước vào nghề, thuật toán Google Panda vẫn là một khái niệm khá mơ hồ vì bạn chưa có nhiều cơ hội va chạm thực tế với các dự án SEO đa dạng. Trên thực tế, thuật toán Google Panda đóng vai trò quan trọng trong việc đánh giá chất lượng nội dung và quyết định thứ hạng của website trên Google.
Nếu bạn chưa hiểu rõ cách thuật toán Google Panda hoạt động, bạn sẽ khó lý giải nguyên nhân website tụt traffic hoặc mất top hàng loạt. Vì vậy, việc nắm vững bản chất, nguyên nhân tác động và cách khắc phục khi bị ảnh hưởng bởi thuật toán Google Panda là bước nền tảng để bạn làm SEO bền vững hơn.
Google Panda là gì và ra đời trong bối cảnh nào?
Thuật toán Google Panda là một bản cập nhật quan trọng trong hệ thống xếp hạng của Google, tập trung vào việc đánh giá chất lượng nội dung website. Thuật toán Google Panda ra đời trong bối cảnh kết quả tìm kiếm bị “bão hòa” bởi nội dung mỏng, sao chép và các trang content farm. Google đã triển khai Panda nhằm làm sạch SERP và ưu tiên những website cung cấp giá trị thực sự cho người dùng.

Google Panda được Google giới thiệu khi nào và nhằm giải quyết vấn đề gì?
Google đã chính thức giới thiệu thuật toán Google Panda vào tháng 2 năm 2011 như một bước đi mạnh mẽ để cải thiện chất lượng kết quả tìm kiếm. Trước thời điểm đó, nhiều website sản xuất nội dung hàng loạt, tối ưu từ khóa quá mức nhưng lại thiếu chiều sâu vẫn có thể xếp hạng cao. Thuật toán Google Panda đã thay đổi cuộc chơi khi Google bắt đầu đánh giá chất lượng nội dung ở cấp độ toàn site thay vì chỉ từng trang riêng lẻ.

Vậy thuật toán Google Panda sinh ra để giải quyết những vấn đề cụ thể nào?
- Nội dung mỏng (thin content) không cung cấp giá trị thực tế cho người đọc
- Nội dung sao chép hoặc trùng lặp (duplicate content) giữa nhiều trang
- Website dạng content farm sản xuất bài viết hàng loạt chỉ để lấy traffic
- Nội dung nhồi nhét từ khóa nhưng thiếu tính chuyên môn
- Trải nghiệm người dùng kém khiến người đọc rời trang nhanh
Google Panda khác gì so với các bản cập nhật thuật toán khác?
Thuật toán Google Panda tập trung gần như hoàn toàn vào chất lượng nội dung và giá trị mà website mang lại cho người dùng. Trong khi nhiều thuật toán khác xử lý backlink, spam kỹ thuật hoặc mục đích tìm kiếm, Panda nhấn mạnh yếu tố “content quality” và đánh giá tổng thể domain. Chính vì vậy, người làm SEO cần hiểu rõ sự khác biệt này để tránh nhầm lẫn khi phân tích nguyên nhân tụt hạng.
So với Google Penguin thì khác gì?
Google Penguin tập trung vào việc xử lý spam backlink và thao túng liên kết, trong khi thuật toán Google Panda tập trung vào nội dung kém chất lượng. Nếu website của bạn có hồ sơ backlink bất thường, Penguin có thể là nguyên nhân; còn nếu nội dung của bạn mỏng và thiếu chiều sâu, Panda mới là yếu tố đáng nghi ngờ.
| Tiêu chí | Google Panda | Google Penguin |
|---|---|---|
| Trọng tâm | Chất lượng nội dung | Backlink spam |
| Phạm vi ảnh hưởng | Toàn website | Hồ sơ liên kết |
| Dấu hiệu phổ biến | Tụt traffic diện rộng | Mất top nhóm từ khóa do link |
So với Google Hummingbird thì khác gì?
Google Hummingbird tập trung vào việc hiểu ngữ nghĩa và mục đích tìm kiếm (search intent), còn thuật toán Google Panda tập trung vào việc đánh giá độ hữu ích và chiều sâu của nội dung. Hummingbird giúp Google hiểu câu hỏi tốt hơn, còn Panda giúp Google chọn ra nội dung chất lượng hơn để hiển thị.
| Tiêu chí | Google Panda | Google Hummingbird |
|---|---|---|
| Mục tiêu chính | Loại bỏ nội dung kém chất lượng | Hiểu search intent |
| Tác động chính | Đánh giá content | Cải thiện truy vấn ngữ nghĩa |
| Đối tượng xử lý | Website nội dung yếu | Cách Google hiểu truy vấn |
So với Google Helpful Content Update thì khác gì?
Google Helpful Content Update có thể được xem là phiên bản hiện đại hóa triết lý của Panda, khi Google tiếp tục ưu tiên nội dung “people-first”. Tuy nhiên, Helpful Content sử dụng hệ thống đánh giá tinh vi hơn và nhấn mạnh vào trải nghiệm thực tế, chuyên môn và giá trị thực tiễn mà người viết mang lại.
| Tiêu chí | Google Panda | Google Helpful Content |
|---|---|---|
| Nền tảng | Chống thin content | Ưu tiên people-first content |
| Thời điểm ra mắt | 2011 | 2022 |
| Tư duy cốt lõi | Nâng cao chất lượng nội dung | Đánh giá nội dung hữu ích thực sự |
Nếu bạn là người làm SEO, bạn nên xem thuật toán Google Panda như nền tảng tư duy về chất lượng nội dung. Khi bạn hiểu rõ Panda khác gì so với các thuật toán khác, bạn sẽ phân tích nguyên nhân tụt hạng chính xác hơn và xây dựng chiến lược content bền vững hơn.
Google Panda hoạt động như thế nào trong hệ thống xếp hạng tìm kiếm?
Thuật toán Google Panda không đơn thuần là một bộ lọc nội dung riêng lẻ mà là một phần trong hệ thống đánh giá chất lượng tổng thể của Google. Google Panda hoạt động bằng cách phân tích tín hiệu nội dung trên quy mô lớn và điều chỉnh thứ hạng dựa trên mức độ hữu ích của website. Khi bạn hiểu cơ chế vận hành này, bạn sẽ biết vì sao một vài trang yếu có thể kéo tụt hiệu suất của cả domain.
Google Panda đánh giá chất lượng nội dung dựa trên những tiêu chí nào?
Để hiểu cách Google Panda hoạt động, bạn cần nhìn vào những yếu tố mà thuật toán này xem là “chất lượng”. Google Panda không chỉ quét mật độ từ khóa mà còn phân tích độ sâu nội dung, mức độ trùng lặp và giá trị thực tế mà bài viết mang lại cho người dùng. Thuật toán Google Panda sử dụng tập hợp nhiều tín hiệu để xác định liệu website có thực sự hữu ích hay chỉ đang cố gắng thao túng thứ hạng.

Thin content được hiểu là gì trong bối cảnh Panda?
Trong bối cảnh của Google Panda, thin content là những trang có nội dung sơ sài, ít thông tin và không giải quyết trọn vẹn vấn đề của người tìm kiếm. Một bài viết chỉ dài vài trăm từ nhưng không cung cấp dữ liệu, ví dụ thực tế hoặc phân tích chuyên sâu thường bị đánh giá là nội dung mỏng. Khi website có quá nhiều trang như vậy, thuật toán Google Panda có thể xem toàn bộ site là kém chất lượng.

Thin content cũng xuất hiện khi website tạo nhiều trang gần giống nhau chỉ để nhắm vào các biến thể từ khóa khác nhau. Việc lặp lại cấu trúc và nội dung tương tự khiến giá trị thực tế bị giảm sút. Vì vậy, người làm SEO cần tập trung vào chiều sâu và tính toàn diện thay vì số lượng bài viết.
Duplicate content ảnh hưởng ra sao đến đánh giá của Panda?
Duplicate content là tình trạng nội dung bị sao chép giữa nhiều trang trong cùng website hoặc từ website khác. Google Panda coi sự trùng lặp này là dấu hiệu cho thấy website thiếu tính nguyên bản và không đóng góp giá trị mới cho hệ sinh thái tìm kiếm. Khi tỷ lệ trùng lặp cao, thứ hạng của nhiều trang có thể bị suy giảm đồng loạt.

Ngoài ra, duplicate content nội bộ cũng khiến Google khó xác định trang nào là phiên bản chính để xếp hạng. Điều này làm phân tán sức mạnh SEO và làm giảm hiệu quả tổng thể của website. Người làm SEO nên kiểm tra kỹ các trang danh mục, thẻ tag và nội dung sản phẩm để tránh lặp lại không cần thiết.
Content farm bị nhận diện như thế nào?
Content farm là mô hình website sản xuất số lượng lớn bài viết với mục tiêu chính là chiếm lĩnh từ khóa và thu hút traffic quảng cáo. Google Panda có khả năng phát hiện các website có mô hình nội dung tương tự nhau, thiếu chuyên môn và không có giá trị chuyên sâu. Khi hệ thống nhận thấy tỷ lệ nội dung kém chất lượng quá cao, website đó có thể bị đánh giá thấp trên diện rộng.

Google Panda không chỉ nhìn vào từng bài viết riêng lẻ mà còn phân tích tổng thể cấu trúc nội dung của domain. Nếu phần lớn bài viết đều ngắn, thiếu dẫn chứng và được xuất bản hàng loạt trong thời gian ngắn, thuật toán có thể coi đó là dấu hiệu của content farm. Vì vậy, bạn cần xây dựng chiến lược nội dung dựa trên chuyên môn và trải nghiệm thực tế thay vì sản xuất đại trà.
Google Panda tác động ở cấp độ trang hay toàn bộ website?
Nhiều người làm SEO thắc mắc liệu Google Panda chỉ ảnh hưởng đến từng trang riêng lẻ hay toàn bộ website. Thực tế cho thấy thuật toán Google Panda đánh giá chất lượng ở cấp độ site-wide, nghĩa là các trang yếu có thể kéo tụt hiệu suất chung của toàn domain. Khi tỷ lệ nội dung kém chất lượng vượt ngưỡng nhất định, cả website có thể bị giảm mức độ tin cậy.
Tuy nhiên, tác động của Panda vẫn biểu hiện rõ ràng ở từng nhóm trang cụ thể. Nếu một chuyên mục có nhiều thin content, chuyên mục đó thường tụt hạng mạnh hơn các phần còn lại. Vì vậy, bạn nên audit theo từng cluster nội dung để xác định khu vực nào đang gây ảnh hưởng tiêu cực.
Các tín hiệu UX có liên quan đến Panda không?
Google Panda được thiết kế để nâng cao trải nghiệm người dùng thông qua việc ưu tiên nội dung chất lượng. Vì vậy, nhiều người làm SEO đặt câu hỏi liệu các tín hiệu UX như bounce rate hay time on site có liên quan trực tiếp đến Panda hay không. Mặc dù Google không công bố chi tiết thuật toán, nhiều phân tích cho thấy trải nghiệm người dùng có mối liên hệ gián tiếp với cách Panda đánh giá website.

Nếu người dùng thường xuyên rời trang nhanh vì nội dung không hữu ích, hệ thống có thể ghi nhận tín hiệu tiêu cực về chất lượng. Ngược lại, nội dung giữ chân người đọc và giải quyết trọn vẹn nhu cầu tìm kiếm sẽ củng cố tín hiệu tích cực.
Những tín hiệu UX thường được xem là có liên quan gồm:
- Thời gian ở lại trang
- Tỷ lệ thoát trang
- Tỷ lệ quay lại kết quả tìm kiếm
- Mức độ tương tác nội dung (scroll, click nội bộ)
Khi bạn tối ưu nội dung theo hướng thực sự hữu ích, bạn không chỉ cải thiện UX mà còn giảm rủi ro bị thuật toán Google Panda đánh giá thấp.
Dấu hiệu nào cho thấy website đang bị Google Panda tác động?
Khi website bắt đầu tụt hiệu suất mà bạn không thay đổi chiến lược SEO hay cấu trúc kỹ thuật, bạn nên nghĩ đến khả năng bị ảnh hưởng bởi thuật toán Google Panda. Google Panda thường không gửi thông báo trực tiếp trong Search Console, vì vậy bạn cần dựa vào dữ liệu để phân tích. Nếu bạn nhận diện đúng tín hiệu, bạn sẽ xử lý vấn đề nhanh hơn và tránh tối ưu sai hướng.
Traffic giảm đột ngột có phải là tín hiệu cảnh báo?
Traffic giảm đột ngột, đặc biệt là organic traffic, có thể là một tín hiệu cảnh báo rõ ràng khi website bị tác động bởi thuật toán Google Panda. Nếu bạn thấy lượng truy cập giảm mạnh trong thời gian ngắn và không liên quan đến yếu tố mùa vụ hay lỗi kỹ thuật, bạn nên kiểm tra lại chất lượng nội dung toàn site. Google Panda thường ảnh hưởng trên diện rộng, vì vậy mức giảm traffic thường xảy ra đồng loạt ở nhiều nhóm bài viết thay vì chỉ một vài trang riêng lẻ.
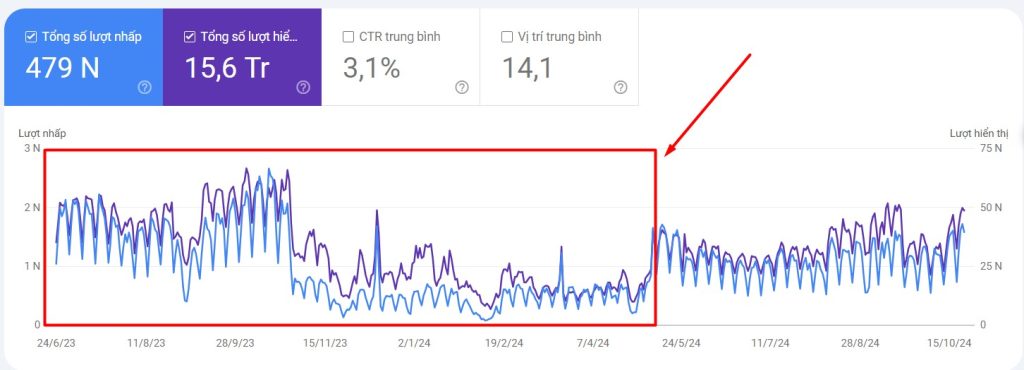
Thứ hạng từ khóa tụt diện rộng có liên quan đến Panda không?
Khi nhiều từ khóa cùng lúc tụt hạng, đặc biệt là các từ khóa thuộc cùng một nhóm nội dung, bạn cần xem xét khả năng website đang bị Google Panda đánh giá thấp về chất lượng. Thuật toán Google Panda có xu hướng tác động ở cấp độ tổng thể, nên sự sụt giảm thường diễn ra trên nhiều URL thay vì một trang đơn lẻ. Nếu bạn thấy các bài viết có nội dung mỏng hoặc trùng lặp đồng loạt mất top, đó là dấu hiệu cho thấy bạn nên audit và nâng cấp lại toàn bộ hệ thống content.
Quy trình kiểm tra website có đang bị Google Panda ảnh hưởng không?
Khi bạn nghi ngờ website bị tác động bởi thuật toán Google Panda, bạn không nên kết luận vội vàng chỉ dựa vào cảm tính. Google Panda không gửi thông báo phạt thủ công, vì vậy bạn cần dựa hoàn toàn vào dữ liệu và logic phân tích. Một quy trình kiểm tra rõ ràng sẽ giúp bạn xác định đúng nguyên nhân và tránh tối ưu sai hướng.

Làm sao đối chiếu thời điểm traffic giảm với lịch sử cập nhật thuật toán?
Khi traffic giảm, bạn cần xác định chính xác thời điểm bắt đầu “gãy” dữ liệu trước khi liên hệ đến thuật toán Google Panda. Việc đối chiếu đúng mốc thời gian giúp bạn tránh nhầm lẫn giữa cập nhật thuật toán và các lỗi kỹ thuật nội bộ. Nếu bạn làm đúng quy trình, bạn sẽ thu hẹp được phạm vi nguyên nhân rất nhanh.
Bạn có thể thực hiện theo các bước sau:
- Bước 1: Xác định thời điểm traffic bắt đầu giảm mạnh:
Bạn sử dụng Google Search Console hoặc Google Analytics 4 để xem dữ liệu theo từng ngày thay vì theo tháng. Bạn cần tìm đúng ngày hoặc khoảng thời gian traffic lao dốc rõ rệt và kiểm tra xem sự sụt giảm xảy ra trên toàn site hay chỉ một nhóm URL cụ thể. - Bước 2: Đối chiếu với lịch sử cập nhật thuật toán:
Sau khi có mốc thời gian cụ thể, bạn cần tra cứu Google Search Status Dashboard hoặc các trang tin SEO uy tín để xem thời điểm đó có bản cập nhật nào liên quan đến chất lượng nội dung hay không. Nếu thời gian trùng với một đợt cập nhật lớn, khả năng website bị ảnh hưởng bởi hệ thống đánh giá chất lượng như Panda sẽ cao hơn. - Bước 3: Phân tích loại cập nhật để khoanh vùng nguyên nhân:
Bạn cần xác định xem bản cập nhật đó có liên quan đến nội dung, spam hay liên kết. Nếu dấu hiệu chính là traffic giảm diện rộng ở các trang nội dung mỏng, bạn nên ưu tiên kiểm tra theo hướng chất lượng content thay vì backlink. - Bước 4: Loại trừ yếu tố kỹ thuật và mùa vụ:
Trước khi kết luận là do thuật toán Google Panda, bạn cần kiểm tra robots.txt, lỗi index, lỗi máy chủ hoặc thay đổi cấu trúc URL. Bạn cũng nên xem xét yếu tố mùa vụ để tránh hiểu nhầm khi nhu cầu tìm kiếm giảm tự nhiên.
Cần audit những nhóm nội dung nào trước tiên?
Khi bạn đã xác định website có khả năng bị ảnh hưởng bởi thuật toán Google Panda, bạn cần bắt đầu audit nội dung một cách có hệ thống. Bạn không nên chỉnh sửa rải rác từng bài viết mà nên ưu tiên các nhóm nội dung có rủi ro cao. Cách làm có chiến lược sẽ giúp bạn tiết kiệm thời gian và xử lý đúng trọng tâm.
Bạn nên ưu tiên kiểm tra:
- Nhóm bài viết có traffic giảm mạnh nhất
- Các trang có nội dung ngắn, ít thông tin
- Các trang có tỷ lệ thoát cao bất thường
- Các cụm nội dung có nhiều bài viết gần giống nhau
- Trang tag, category hoặc trang lọc có nội dung trùng lặp
Lưu ý: bạn không nên xóa hàng loạt nội dung ngay lập tức. Bạn cần phân loại rõ bài nào nên cập nhật, bài nào nên gộp và bài nào nên loại bỏ hoàn toàn để cải thiện chất lượng tổng thể domain.
Những công cụ nào hỗ trợ phân tích tác động của Panda hiệu quả nhất?
Để phân tích tác động của thuật toán Google Panda một cách chính xác, bạn cần kết hợp nhiều công cụ thay vì chỉ nhìn vào một nguồn dữ liệu. Mỗi công cụ s ẽ cung cấp một góc nhìn khác nhau về hiệu suất nội dung và hành vi người dùng.
Bạn có thể sử dụng:
- Google Search Console để theo dõi hiệu suất truy vấn và URL
- Google Analytics 4 để phân tích hành vi người dùng và tỷ lệ tương tác
- Công cụ crawl website (như Screaming Frog) để phát hiện thin content và trùng lặp
- Công cụ đo biến động SERP để kiểm tra mức độ ảnh hưởng của cập nhật thuật toán
Khi bạn kết hợp dữ liệu từ nhiều nguồn, bạn sẽ có cái nhìn toàn diện hơn về tác động của thuật toán Google Panda và đưa ra quyết định tối ưu chính xác hơn.
Cách khắc phục website khi bị Google Panda là gì?
Khi website bị ảnh hưởng bởi thuật toán Google Panda, bạn không thể xử lý bằng một vài chỉnh sửa nhỏ lẻ. Google Panda đánh giá chất lượng nội dung ở mức tổng thể, vì vậy bạn cần cải thiện toàn bộ hệ thống content thay vì tối ưu từng trang rời rạc. Nếu bạn có quy trình rõ ràng và kiên nhẫn thực hiện, website hoàn toàn có thể phục hồi.

Có nên xóa hay gộp các bài viết thin content?
Khi bạn phát hiện nhiều bài viết có nội dung mỏng, bạn cần phân loại trước khi quyết định xóa hay giữ lại. Nếu bài viết không mang lại traffic, không có backlink và nội dung trùng lặp, bạn nên cân nhắc gộp vào một bài viết chuyên sâu hơn. Việc gộp nội dung giúp tăng độ toàn diện và tránh phân tán sức mạnh SEO.

Tuy nhiên, bạn không nên xóa hàng loạt chỉ vì bài viết ngắn. Một số trang vẫn có giá trị nếu bạn mở rộng nội dung và bổ sung thông tin chuyên môn. Bạn cần đánh giá dựa trên dữ liệu thực tế thay vì cảm tính để tránh làm mất đi tài nguyên có tiềm năng.
Khi nào nên sử dụng chiến lược content pruning?
Bạn nên sử dụng chiến lược content pruning khi website có quá nhiều bài viết kém chất lượng và gây ảnh hưởng đến toàn domain. Content pruning giúp bạn loại bỏ hoặc hợp nhất những nội dung không mang lại giá trị thực sự. Khi tỷ lệ thin content cao, thuật toán Google Panda có thể đánh giá website là kém chất lượng trên diện rộng.

Trước khi thực hiện pruning, bạn cần phân tích traffic, impression và mức độ liên quan của từng bài viết. Nếu một trang không có dữ liệu tích cực trong thời gian dài, bạn có thể cân nhắc redirect hoặc gộp vào bài viết mạnh hơn. Cách làm có chiến lược sẽ giúp website “nhẹ” hơn và tập trung vào nội dung chất lượng.
Khi nào nên cập nhật và mở rộng nội dung thay vì xóa?
Bạn nên cập nhật và mở rộng nội dung khi bài viết vẫn có impression hoặc tiềm năng từ khóa tốt. Nếu nội dung chỉ thiếu chiều sâu hoặc chưa đầy đủ thông tin, bạn có thể bổ sung ví dụ thực tế, dữ liệu mới và cấu trúc lại bài viết. Cách làm này giúp bạn giữ lại URL đã có lịch sử SEO thay vì xây dựng lại từ đầu.
Việc mở rộng nội dung còn giúp bạn tăng topical authority cho toàn bộ website. Khi bài viết được nâng cấp toàn diện, Google Panda sẽ ghi nhận tín hiệu tích cực về chất lượng. Bạn nên ưu tiên cải thiện trước khi quyết định loại bỏ hoàn toàn.
Làm sao tối ưu lại cấu trúc nội dung để tăng chất lượng tổng thể?
Khi website bị ảnh hưởng bởi Google Panda, bạn cần xem lại toàn bộ cấu trúc nội dung thay vì chỉ chỉnh sửa từng bài viết riêng lẻ. Cấu trúc rời rạc, thiếu liên kết nội bộ và trùng lặp chủ đề thường làm giảm giá trị tổng thể của domain. Bạn nên xây dựng lại hệ thống nội dung theo cụm chủ đề rõ ràng.
Một cấu trúc nội dung tốt sẽ giúp Google hiểu mối quan hệ giữa các bài viết và xác định đâu là trang trọng tâm. Khi nội dung được tổ chức logic, website sẽ thể hiện rõ chuyên môn và độ chuyên sâu. Đây là yếu tố quan trọng để cải thiện đánh giá chất lượng từ hệ thống xếp hạng.
Topic cluster có giúp phục hồi sau Panda không?
Mô hình topic cluster giúp bạn gom các bài viết liên quan về một chủ đề lớn và liên kết chúng với một bài pillar trung tâm. Khi bạn triển khai đúng cách, Google sẽ hiểu rằng website có chuyên môn sâu về chủ đề đó. Điều này giúp cải thiện tín hiệu chất lượng mà Google Panda đánh giá.

Topic cluster cũng giúp bạn hạn chế trùng lặp nội dung giữa các bài viết. Thay vì viết nhiều bài na ná nhau, bạn phân bổ nội dung theo vai trò cụ thể trong cụm chủ đề. Cách làm này giúp website trở nên mạch lạc và chuyên nghiệp hơn.
Internal link nên được cải thiện như thế nào?
Internal link đóng vai trò quan trọng trong việc phân phối sức mạnh SEO và hướng dẫn Google crawl nội dung hiệu quả. Khi website thiếu liên kết nội bộ, các bài viết quan trọng có thể không được ưu tiên đúng mức. Bạn nên xây dựng liên kết nội bộ dựa trên mối quan hệ chủ đề thay vì chèn link ngẫu nhiên.

Bạn cần đảm bảo mỗi bài viết quan trọng đều được liên kết từ các bài liên quan trong cùng cụm chủ đề. Anchor text nên rõ ràng và phản ánh đúng nội dung trang đích. Khi hệ thống liên kết được tối ưu tốt, chất lượng tổng thể website sẽ được cải thiện đáng kể.
Làm thế nào để xây dựng lại E-E-A-T sau khi bị ảnh hưởng?
Khi website bị tác động bởi Google Panda, bạn cần củng cố lại yếu tố E-E-A-T thông qua nội dung có chuyên môn và trải nghiệm thực tế. Bạn nên bổ sung thông tin tác giả, nguồn tham khảo đáng tin cậy và dẫn chứng cụ thể trong bài viết. Điều này giúp Google và người đọc đánh giá cao mức độ uy tín của website.

Ngoài ra, bạn nên tập trung vào việc chia sẻ kiến thức thực tế thay vì chỉ tổng hợp thông tin chung chung. Nội dung có chiều sâu, có quan điểm chuyên môn và dữ liệu minh chứng sẽ tạo ra sự khác biệt rõ ràng. Khi E-E-A-T được cải thiện, khả năng phục hồi thứ hạng sẽ cao hơn.
Sau khi tối ưu, bao lâu website có thể phục hồi thứ hạng?
Thời gian phục hồi sau khi bị ảnh hưởng bởi Google Panda phụ thuộc vào mức độ vấn đề và quy mô website. Nếu bạn cải thiện nội dung một cách toàn diện và nhất quán, bạn có thể thấy tín hiệu tích cực sau vài tuần đến vài tháng. Tuy nhiên, bạn cần kiên nhẫn vì hệ thống đánh giá chất lượng thường cần thời gian để ghi nhận thay đổi.
Bạn không nên mong đợi kết quả ngay lập tức sau khi chỉnh sửa vài bài viết. Google cần crawl lại, đánh giá lại và so sánh với mặt bằng chung của thị trường. Khi bạn duy trì chất lượng nội dung ổn định trong dài hạn, thứ hạng sẽ có cơ hội phục hồi bền vững.
Những lầm tưởng về thuật toán Google Panda
Bạn có nên xóa nội dung để giải quyết vấn đề của Google Panda không?
Vào năm 2017, Gary Illyes của Google đã nói trên Twitter : “Chúng tôi khuyên bạn không nên xóa nội dung nói chung khi dính Panda, thay vào đó hãy thêm nhiều nội dung HighQ hơn”.
“Nhìn chung, chất lượng của trang web cần được cải thiện đáng kể để chúng tôi có thể tin tưởng vào nội dung. Đôi khi những gì chúng ta thấy với một trang web như vậy sẽ có rất nhiều nội dung mỏng, có thể có nội dung bạn đang tổng hợp từ các nguồn khác, có thể có nội dung do người dùng tạo, nơi mọi người gửi bài viết có chất lượng thấp và đó là tất cả những thứ bạn có thể muốn xem và nói tôi có thể làm gì; mặt khác, nếu tôi muốn giữ những bài báo này, có thể ngăn chúng xuất hiện trong tìm kiếm. Có thể sử dụng thẻ noindex cho những thứ này. ”
John Mueller cũng nói trong video
Phản ứng của Google luôn là ngăn lập chỉ mục hoặc cải thiện nội dung – không bao giờ cắt hoàn toàn trừ khi làm như vậy là một động thái xây dựng thương hiệu.
Nói chung, việc xóa nội dung nên được cân nhắc về mặt thương hiệu tổng thể của trang web của bạn, thay vì một động thái sẽ xóa bỏ hình phạt Panda.
Google Panda và nội dung do người dùng tạo
Google Panda không nhắm mục tiêu cụ thể đến nội dung do người dùng tạo. Mặc dù Panda có thể nhắm mục tiêu đến nội dung do người dùng tạo, nhưng nó có xu hướng ảnh hưởng đến các trang web sản xuất nội dung chất lượng thấp – chẳng hạn như các bài đăng spam của khách hoặc các diễn đàn chứa đầy spam.

Không xóa nội dung do người dùng tạo của bạn, cho dù đó là trên diễn đàn, bình luận blog hoặc ý kiến đóng góp bài viết, đơn giản vì bạn nghe nói rằng nó là “xấu” hoặc được giới thiệu như một giải pháp “Panda proof”. Thay vào đó hãy nhìn nó từ góc độ chất lượng.
Nhiều trang web xếp hạng cao dựa vào nội dung do người dùng tạo – vì vậy nhiều trang web sẽ mất lưu lượng truy cập và xếp hạng đáng kể chỉ vì họ đã xóa loại nội dung đó. Ngay cả những nhận xét được đưa ra trên một bài đăng blog cũng có thể khiến nó được xếp hạng và thậm chí có được một đoạn trích nổi bật.
Số từ không phải là một yếu tố
Số lượng từ là một khía cạnh khác của Panda mà các chuyên gia SEO thường hiểu nhầm. Nhiều trang web mắc sai lầm khi từ chối xuất bản bất kỳ nội dung nào trừ khi nội dung đó vượt quá số từ nhất định, với 250 từ và 350 từ thường được trích dẫn. Thay vào đó, Google khuyên bạn nên suy nghĩ về số lượng từ mà nội dung cần để thành công đối với người dùng.
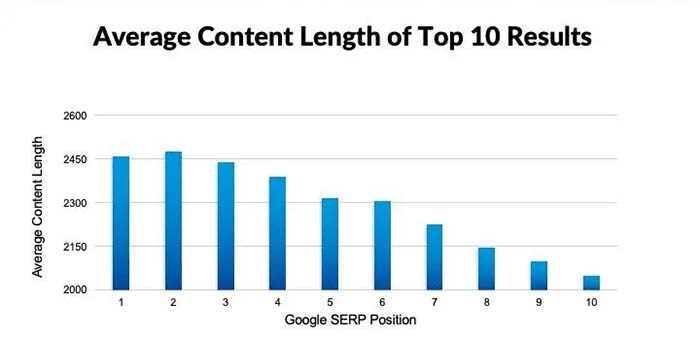
Ví dụ: Có rất nhiều trang có rất ít nội dung chính, nhưng Google cho rằng trang đó đủ chất lượng để kiếm được đoạn trích nổi bật cho truy vấn. Trong một trường hợp, nội dung chính chỉ vỏn vẹn 63 từ và nhiều người sẽ khó viết về chủ đề này theo cách không spam với độ dài hơn 350 từ. Vì vậy, bạn chỉ cần đủ từ để trả lời truy vấn.
Affiliate links và Quảng cáo không được nhắm mục tiêu trực tiếp
Các trang web Affiliate và các trang web “được tạo cho AdSense” thường bị Google Panda tấn công nhiều hơn các trang web khác, nhưng điều này không phải vì nó nhắm mục tiêu cụ thể đến chúng. Người phát ngôn của Google nói với TheSEMPost rằng
“Một ví dụ điển hình là khi chức năng chính của trang web là đưa người dùng đến các trang web khác thông qua quảng cáo hoặc liên kết affiliate, nội dung có sẵn trên internet hoặc được sản xuất vội vàng và được xây dựng rõ ràng để thu hút khách truy cập từ các công cụ tìm kiếm.”
Mueller nói tiếp :
“Nhưng đồng thời, chúng tôi thấy rất nhiều người làm affiliate về cơ bản chỉ là những người lười biếng sao chép và dán các nguồn cấp dữ liệu mà họ nhận được và xuất bản chúng trên trang web của họ. Và các loại nội dung chất lượng thấp hơn, nội dung mỏng, là thứ thực sự khó để chúng tôi hiển thị trong tìm kiếm. ”
Nói cách khác, những trang web này đang bị tấn công vì những lý do tương tự: chúng không cung cấp nội dung hấp dẫn, độc đáo, hấp dẫn.
Các bản Update Google Panda qua các thời kỳ
Google Panda gần như chắc chắn là thuật toán có hồ sơ công khai rộng rãi nhất về các ngày công khai cho các bản cập nhật liên quan của nó. Một phần lý do của việc này là do Panda được chạy bên ngoài từ thuật toán cốt lõi của Google và kết quả là điểm số nội dung chỉ bị ảnh hưởng vào hoặc gần ngày cập nhật Panda mới.
Điều này tiếp tục cho đến ngày 11 tháng 6 năm 2013, khi Cutts trả lời tại SMX Advanced rằng, mặc dù Panda không được tích hợp trực tiếp vào thuật toán cốt lõi của Google, nhưng dữ liệu của nó được cập nhật hàng tháng và triển khai chậm trong suốt tháng, chứ không tác động đột ngột trên toàn ngành với các bản cập nhật Panda.
Quy ước đánh số hơi khó hiểu.
Người ta mong đợi các bản cập nhật cốt lõi cho thuật toán của Panda sẽ tương ứng với 1.0, 2.0, 3.0 và 4.0, nhưng không có bản cập nhật nào được gọi là 3.0 và 3.1 không phải là bản cập nhật cốt lõi cho thuật toán Panda.
Làm mới dữ liệu, cập nhật kết quả tìm kiếm chứ không phải chính thuật toán Panda, thường được đánh số như bạn mong đợi đối với các bản cập nhật phần mềm (3.2, 3.4, 3.5, v.v.). Tuy nhiên, có quá nhiều lần làm mới dữ liệu cho phiên bản 3 của thuật toán, trong một thời gian, quy ước đặt tên này đã bị bỏ qua và ngành công nghiệp gọi chúng chỉ đơn giản bằng tổng số bản cập nhật Panda (cả bản làm mới và bản cập nhật cốt lõi).
Ngay cả sau khi xử lý được quy ước đặt tên này, vẫn không hoàn toàn rõ ràng liệu tất cả các bản cập nhật Panda nhỏ chỉ là làm mới dữ liệu hay một số trong số chúng cũng kết hợp các tín hiệu mới.

Bất kể, dòng thời gian của các bản cập nhật Panda, ít nhất, cũng được biết đến và như sau:
- 1.0 : Ngày 23 tháng 2 năm 2011. Lần lặp lại đầu tiên của bản cập nhật thuật toán chưa được đặt tên khi đó đã được giới thiệu (12% số truy vấn bị ảnh hưởng), gây sốc cho ngành công nghiệp tối ưu hóa công cụ tìm kiếm, nhiều công ty lớn và kết thúc hiệu quả mô hình kinh doanh “trang trại nội dung” như nó tồn tại vào thời điểm đó.
- 2.0 (# 2) : Ngày 11 tháng 4 năm 2011. Bản cập nhật đầu tiên cho thuật toán Panda lõi. Bản cập nhật này kết hợp các tín hiệu bổ sung, chẳng hạn như các trang web mà người dùng Google đã chặn.
- 2.1 (# 3) : Ngày 9 tháng 5 năm 2011. Đầu tiên trong ngành gọi đây là Panda 3.0, nhưng Google đã làm rõ ràng đó chỉ là một bản làm mới dữ liệu, cũng như các bản cập nhật 2.x sắp tới.
- 2.2 (# 4) : Ngày 21 tháng 6 năm 2011
- 2.3 (# 5) : Ngày 23 tháng 7 năm 2011
- 2.4 (# 6) International: Ngày 12 tháng 8 năm 2011. Panda được triển khai trên toàn thế giới cho tất cả các quốc gia nói tiếng Anh và các quốc gia không nói tiếng Anh, ngoại trừ Nhật Bản, Trung Quốc và Hàn Quốc.
- 2.5 (# 7) và Panda-Related Flux : 28 tháng 9 năm 2011. Sau bản cập nhật này, vào ngày 5 tháng 10 năm 2011, Cutts thông báo “mong đợi một số thông lượng liên quan đến Panda trong vài tuần tới”. Ngày thông lượng được xác nhận là ngày 3 tháng 10 và ngày 13 tháng 10.
- 3.0 (# 8): Ngày 19 tháng 10 năm 2011. Google đã thêm một số tín hiệu mới vào thuật toán Panda và cũng tính toán lại cách thuật toán ảnh hưởng đến các trang web.
- 3.1 (# 9): Ngày 18 tháng 11 năm 2011. Google đã công bố một đợt làm mới nhỏ, tác động đến ít hơn 1 phần trăm tìm kiếm.
- 3.2 (# 10) : Ngày 18 tháng 1 năm 2012. Google xác nhận việc làm mới dữ liệu đã xảy ra vào ngày này.
- 3.3 (# 11) : Ngày 23 tháng 2 năm 2012. Làm mới dữ liệu.
- 3.4 (# 12) : Ngày 23 tháng 3 năm 2012
- 3.5 (# 13) : Ngày 19 tháng 4 năm 2012
- 3.6 (# 14) : Ngày 27 tháng 4 năm 2012
- 3.7 (# 15) : Ngày 8 tháng 6 năm 2012. Việc làm mới dữ liệu mà các công cụ xếp hạng đề xuất là gây ảnh hưởng nặng nề hơn so với các bản cập nhật gần đây khác.
- 3.8 (# 16) : Ngày 25 tháng 6 năm 2012
- 3.9 (# 17) : Ngày 24 tháng 7 năm 2012
- 3.9.1 (# 18) : Ngày 20 tháng 8 năm 2012. Một bản cập nhật tương đối nhỏ đánh dấu sự khởi đầu của quy ước đặt tên mới do ngành chỉ định.
- 3.9.2 (# 19) : 18 tháng 9 năm 2012
- # 20 : Ngày 27 tháng 9 năm 2012. Một bản cập nhật Panda tương đối lớn cũng đánh dấu sự khởi đầu của một quy ước đặt tên khác. Ngành công nghiệp đã nhận ra sự lúng túng của quy ước đặt tên 9.xx và nhận ra rằng các bản cập nhật cho cái mà họ gọi là Panda 3.0 có thể tiếp tục xảy ra trong một thời gian rất dài.
- # 21 : Ngày 5 tháng 11 năm 2012
- # 22 : Ngày 21 tháng 11 năm 2012
- # 23 : Ngày 21 tháng 12 năm 2012. Làm mới dữ liệu có tác động hơn một chút.
- # 24 : Ngày 22 tháng 1 năm 2013
- # 25 : Ngày 14 tháng 3 năm 2013. Bản cập nhật này đã được thông báo trước và các công cụ cho rằng nó xảy ra vào khoảng ngày này. Cutts dường như gợi ý rằng đây sẽ là bản cập nhật cuối cùng trước khi Panda được tích hợp trực tiếp vào thuật toán Google. Tuy nhiên, sau đó rõ ràng rằng đây không phải là những gì đang xảy ra.
- “Dance” : Ngày 11 tháng 6 năm 2013. Đây không phải là ngày cập nhật. Tuy nhiên, ngày Cutts đã làm rõ Panda sẽ không được tích hợp trực tiếp vào thuật toán, mà là nó sẽ cập nhật hàng tháng với các đợt phát hành chậm hơn nhiều, thay vì làm mới dữ liệu đột ngột như trước đây.
- “Phục hồi” : Ngày 18 tháng 7 năm 2013. Bản cập nhật này dường như là một sự điều chỉnh để sửa một số hoạt động quá khắc nghiệt của Panda.
- 4.0 (# 26) : Ngày 19 tháng 5 năm 2014. Một bản cập nhật Panda lớn (tác động đến 7,5 phần trăm truy vấn) đã xảy ra vào ngày này. Hầu hết trong ngành tin rằng đây là một bản cập nhật cho thuật toán Panda, không chỉ là một bản làm mới dữ liệu, đặc biệt là theo tuyên bố của Cutts về việc triển khai chậm.
- 4.1 (# 27) : Ngày 23 tháng 9 năm 2014. Một bản cập nhật lớn khác (tác động từ 3 đến 5 phần trăm các truy vấn) bao gồm một số thay đổi đối với thuật toán Panda. Do quá trình phát hành chậm nên ngày chính xác vẫn chưa rõ ràng, nhưng thông báo được đưa ra vào ngày 25 tháng 9.
- 4.2 (# 28) : Ngày 17 tháng 7 năm 2015. Google đã công bố bản cập nhật Panda sẽ mất vài tháng để triển khai. Do tính chất chậm của quá trình triển khai, không rõ mức độ tác động đáng kể hoặc chính xác thời điểm nó xảy ra. Đây là bản cập nhật Panda cuối cùng được xác nhận.
- Kết hợp thuật toán cốt lõi : Ngày 11 tháng 1 năm 2016. Google xác nhận rằng Panda đã được kết hợp vào thuật toán cốt lõi của Google , rõ ràng là một phần của quá trình triển khai chậm chạp vào ngày 17 tháng 7 năm 2015. Nói cách khác, Panda không còn là một bộ lọc được áp dụng cho thuật toán Google sau khi nó hoạt động mà được kết hợp như một tín hiệu xếp hạng cốt lõi khác của nó. Tuy nhiên, người ta đã làm rõ rằng điều này không có nghĩa là trình phân loại Panda hoạt động trong thời gian thực.
Lời kết
Tại thời điểm hiện tại hay là trong tương lai, bạn nên ghi nhớ những khái niệm cốt lõi của Google Panda. Tránh các chiến thuật SEO mũ đen và liên kết spam và tập trung vào nội dung chất lượng cho người dùng và trải nghiệm của họ.
Tên Google Panda có thể không xuất hiện trong thông báo của các bản cập nhật, nhưng các nguyên tắc của Panda vẫn còn phù hợp cho đến ngày nay và cả sau này.
- Hướng dẫn thêm về việc xây dựng trang web chất lượng cao
- Google Panda
- A Complete Guide to the Google Panda Update: 2011-21
- Google Panda (Moz)
Nguồn: vietmoz.edu.vn
Bản quyền thuộc về Đào tạo SEO VietMoz
Vui lòng không copy khi chưa được sự đồng ý của tác giả
