Như chúng ta đã biết SEO là một quy trình nâng cao thứ hạng của website trên các công cụ tìm kiếm giúp người dùng có thể tìm thấy trang web dễ dàng hơn trên bảng kết quả tìm kiếm (SERP).
Và để nội dung của bạn có thể xuất hiện trên SERP trước tiên nội dung của bạn phải hiển thị cho các công cụ tìm kiếm. Vì nếu không thể tìm thấy trang web của bạn, website của bạn sẽ không bao giờ xuất hiện trong SERP.
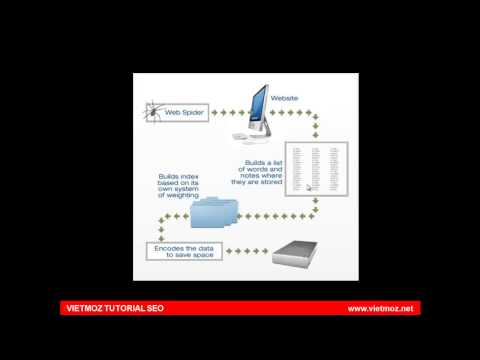
Công cụ tìm kiếm hoạt động như thế nào?
Có ba chức năng chính của công cụ tìm kiếm:
- Thu thập thông tin (Crawling): Tìm kiếm các thông tin trên môi trường internet, truy cập vào những nội dung được tìm thấy và thu thập dữ liệu thông qua các đoạn mã trong website.
- Lập chỉ mục (Indexing): Khả năng sắp xếp và lưu trữ thông tin sau khi được tìm thấy. Khi đã được lập chỉ mục, trang kết quả sẽ được đánh dấu với từng truy vấn liên quan và được hiển thị trên SERP khi có người tìm kiếm.
- Xếp hạng (Ranking): Sắp xếp thứ tự của các website trên SERP với mục đích cung cấp các kết quả phù hợp nhất cho các truy vấn sau đó mới đến các kết quả ít liên quan nhất.
Xem thêm video giải thích về cơ chế hoạt động của công cụ tìm kiếm

Crawling là gì?
Crawling là quá trình thu thập nội dung mới của công cụ tìm kiếm được thực hiện bởi Googlebot.
Googlebot sẽ đi theo các liên kết được tìm thấy trong trang web để tìm các URL mới. Bằng cách này trình thu thập thông tin của Google có thể tìm thấy nội dung và đưa vào chỉ mục có tên Caffeine – một cơ sở dữ liệu khổng lồ của Google.
Indexing là gì?
Các công cụ tìm kiếm quản lý một cơ sở dữ liệu khổng lồ về tất cả những nội dung mà họ đã tìm thấy. Bằng việc lưu trữ và xử lý thông tin, Google có thể cung cấp các câu trả lời cho hầu hết những câu hỏi của người tìm kiếm.
Ranking là gì?
Khi ai đó thực hiện tìm kiếm, các công cụ tìm kiếm sẽ tìm trong chỉ mục của mình để tìm những nội dung liên quan và sắp xếp kết quả đưa ra câu trả lời cho người tìm kiếm. Thứ tự các kết quả tìm kiếm được xếp hạng từ trên xuống dưới. Về lý thuyết, thứ hạng trang web càng cao thì công cụ tìm kiếm tin rằng trang web đó có mức độ liên quan đến truy vấn tìm kiếm càng cao.
Crawling: Công cụ tìm kiếm có thể tìm thấy các trang quan trọng nhất của bạn không?
Như bạn đã biết về Crawling, nếu bạn đã có một trang web bạn có thể kiểm tra xem có bao nhiêu trang của bạn nằm trong chỉ mục. Điều này sẽ giúp bạn kiểm soát các trang được lập chỉ mục trong Google một cách dễ dàng hơn.
Cách để kiểm tra chỉ mục trên website đó là sử dụng toán tử tìm kiếm: “site:domain.com”, các kết quả trả về sẽ là những trang thuộc website của bạn được lập chỉ mục trên Google.

Số lượng kết quả Google hiển thị có thể không chính xác 100%, nhưng chắc chắn sẽ mang lại cho bạn những thông tin hữ ích về tình trạng lập chỉ mục trên website của bạn.
Để có kết quả chuẩn xác hơn, bạn có thể dùng báo cáo Trạng thái lập chỉ mục trong Google Search Console. Bạn có thể đăng ký tài khoản Google Search Console miễn phí nếu bạn chưa có. Sau đó bạn có thể có thêm nhiều thông tin hữu ích nữa về website của bạn trên công cụ Google Search Console.
Nếu bạn không tìm thấy website của mình trong kết quả tìm kiếm, có thể do một vài nguyên nhân dưới đây:
- Bạn mới ra mắt trang web và chưa được thu thập thông tin.
- Website của bạn không có bất kỳ trang web nào liên kết tới.
- Các thanh điều hướng trên website của bạn khiến Googlebot gặp khó khăn trong quá trình thu thập dữ liệu.
- Trang web của bạn có chứa các đoạn mã chặn các robot thu thập dữ liệu của công cụ tìm kiếm.
- Tên miền của bạn có thể đã bị Google phạt vì lịch sử sử dụng các chiến thuật spam.
Trong thực tế có khá nhiều URL mà bạn sẽ không muốn Googlebot tìm thấy. Ví dụ như các URL trùng lặp, các trang thử nghiệm hoặc những URL có nội dung mỏng, v.v.
Để điều hướng Googlebot ra khỏi các trang nào đó, bạn hãy sử dụng robots.txt.
Robots.txt
Tệp robots.txt được đặt trong thư mục gốc của các trang web (ví dụ như của VietMoz: https://vietmoz.edu.vn/robots.txt), trong file robots.txt bạn có thể đề xuất từ chối cho phép Googlebot thu thập dữ liệu của một trang nào đó hoặc một thư mục nào đó. Bạn cũng có thể tìm hiểu thêm các lệnh robots.txt cụ thể tại đây.
Cách Googlebot xử lý tệp robots.txt
- Nếu Googlebot không tìm thấy tệp robots.txt cho một trang web, nó sẽ tiến hành thu thập dữ liệu trang web.
- Nếu Googlebot tìm thấy tệp robots.txt nó sẽ tuân theo các đề xuất và tiến hành thu thập dữ liệu trang web.
- Nếu Googlebot gặp lỗi khi cố gắng truy cập vào file robots.txt của trang web và không thể xác định tệp đó có tồn tại hay không nó sẽ không thu thập dữ liệu của trang web.
Một số chuyên gia bảo mật khuyên chúng ta nên đặt thẻ Noindex cho các trang mà chúng ta muốn chặn Googlebot thay vì chèn chúng vào tệp robots.txt.
Googlebot sẽ gặp khó khăn khi tìm kiếm một trang trên trang web của bạn nếu như nó có quá ít liên kết trỏ tới. Đây cũng là sai lầm của khá nhiều quản trị viên khi xây dựng cấu trúc website khi để những trang đơn lẻ và gần như không thể tìm thấy trên website.
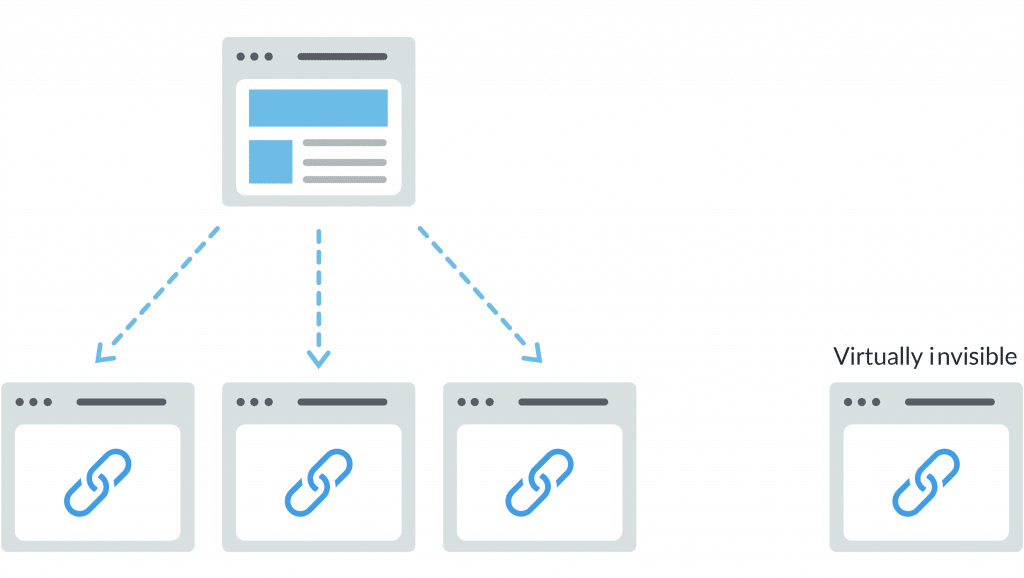
Website của bạn có đang sử dụng sơ đồ trang web không?
Sơ đồ trang web là một danh sách các URL trên website của bạn, trình thu thập dữ liệu của Google có thể sử dụng nó để thuận tiện hơn trong việc khám phá và lập chỉ mục nội dung. Tham khảo cách tạo sơ đồ trang web theo tiêu chuẩn của Google tại đây.
Lưu ý rằng, ngay cả khi website của bạn chỉ là 1 Landing Page và không có bất kỳ trang nào khác, bạn vẫn nên tạo sitemap và gửi cho Google nhé.
Một số lỗi khi Googlebot gặp phải khi truy cập tới trang web của bạn
Trong quá trình thu thập dữ liệu sẽ có nhiều lỗi có thể xảy ra, các lỗi này thông thường sẽ được tổng hợp trong báo cáo của Google Search Console. Dưới đây là một số lỗi phổ biến Googlebot sẽ gặp:
Mã 4xx: Googlebot sẽ không thể truy cập nội dung của bạn, lỗi phổ biến nhất của 4xx là trạng thái 404 not found. Khi gặp lỗi này Googlebot sẽ không thể truy cập URL và sẽ không thu thập được bất kỳ dữ liệu nào trên trang web. Và tất nhiên đối với người dùng khi gặp lỗi 404, họ cũng sẽ rời khỏi trang web của các bạn.
Mã 5xx: Đây là lỗi thường gặp khi website của bạn có sự cố về máy chủ. Khi gặp vấn đề này Googlebot cũng sẽ từ chối thu thập dữ liệu.
Một trong những cách tốt nhất để xử lý các lỗi trên đó là sử dụng mã chuyển hướng cho trang web. Bạn có thể thực hiện các lệnh chuyển hướng vĩnh viễn (mã redirect 301) hoặc chuyển hướng tạm thời (mã trạng thái 302).
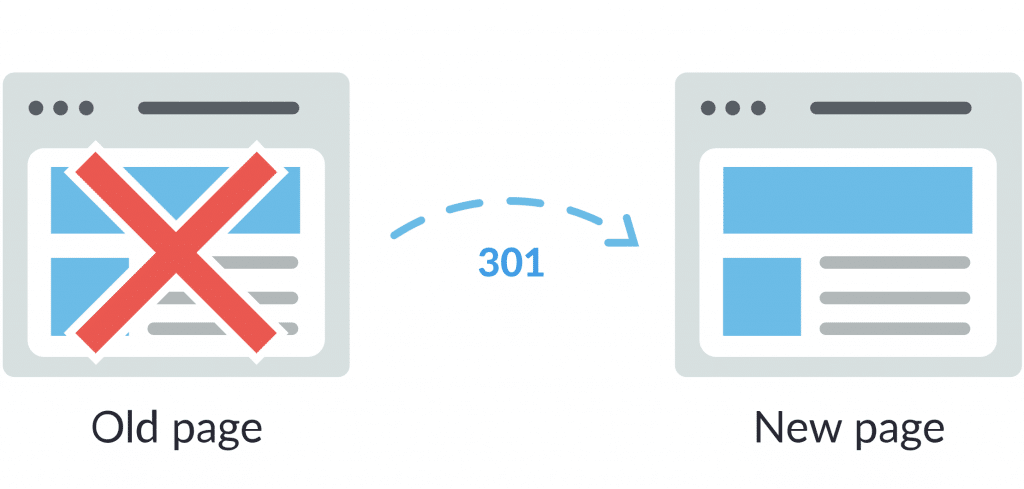
Bạn có thể tạo các mã trạng thái 301 để chuyển hướng các trang bị lỗi về một trang khác, điều này sẽ giúp người dùng không gặp phải các trang lỗi 404. Tuy nhiên mã trạng thái 301 này được khuyến cáo rằng hãy cân nhắc khi sử dụng. Vì có thể làm tụt hạng nội dung trang trước đó.
Để an toàn hơn bạn có thể sử dụng mã chuyển hướng 302, cách này giống như bạn tạo 1 đường vòng tạm thời. Sau khi khắc phục được đường dẫn bị lỗi bạn có thể gỡ bỏ trạng thái 302 và khôi phục website như cũ.
Để hiểu thêm về các mã trạng thái http bạn có thể tham khảo thêm bài viết tôi đã chia sẻ tại đây.
Indexing: Công cụ tìm kiếm lưu trữ trang web của bạn như thế nào?
Nếu trang web của bạn đã được thu thập thông tin, việc tiếp theo bạn cần đảm bảo rằng các bài viết có thể được lập chỉ mục. Trong quá trình thu thập thông tin trên trang, công cụ tìm kiếm sẽ phân tích và lưu chữ trong chỉ mục của nó.
Làm sao để biết Googlebot thu thập thông tin của mình như thế nào?
Bạn có thể sử dụng bản lưu Cache của trang web được chia sẻ trên Google tìm kiếm. Để xem bản lưu cache, bạn lên Google tìm kiếm và nhấp chuột vào mũi tên bên cạnh URL và chọn Bản lưu để xem (hoặc Cached trong ngôn ngữ tiếng Anh)

Một URL đã được lập chỉ mục thì có tồn tại vĩnh viễn không?
Không, có nhiều lý do các trang đã được lập sẽ bị xóa khỏi chỉ mục bao gồm:
- Trang kết quả trả về gặp lỗi không tìm thấy 4xx hoặc lỗi máy chủ 5xx.
- URL đã được thêm thẻ meta cấm các rô bốt lập chỉ mục.
- URL vi phạm nguyên tắc quản trị trang web của công cụ tìm kiếm và bị xóa khỏi chỉ mục.
- URL đã chặn thu thập thông tin bởi việc yêu cầu đăng nhập để có thể truy cập trang.
Trong trường hợp bạn muốn yêu cầu lập chỉ mục, bạn có thể sử dụng tính năng Tìm nạp như Google và chức năng “Yêu cầu lập chỉ mục” để gửi các URL của trang web đến chỉ mục của Google.
Cho các công cụ tìm kiếm biết cách lập chỉ mục trang web của bạn
Sử dụng các thẻ meta robot để yêu cầu trình thu thập dữ liệu của công cụ tìm kiếm tuân thủ. Bằng cách thêm các thẻ meta robot trong <head> của các trang HTML
index/noindex khi gặp thẻ này các công cụ tìm kiếm sẽ biết quyền được thu thập dữ liệu hay không. Nếu không muốn thu thập dữ liệu, bạn hãy sử dụng thẻ “noindex”, còn nếu cho phép bạn hãy dùng thẻ “index”. Bất kỳ trang nào bạn cảm thấy không muốn Google lập chỉ mục hãy cài thẻ noindex cho trang đó.
follow/nofollow lệnh này yêu cầu các công cụ tìm kiếm có được phép theo dõi các liên kết trong trang web hay không. Khi bạn thêm thuộc tính nofollow vào liên kết, các công cụ tìm kiếm sẽ không theo dõi hoặc chuyển đến các liên kết trên trang. Theo mặc định, tất cả các trang đều được gắn thẻ “follow”.
noarchive lệnh này được sử dụng để hạn chế công cụ tìm kiếm lưu bản sao được lưu trong bộ nhớ Cache của trang. Các thẻ này thường được áp dụng cho các trang thương mại điện tử, vì có thể giá sản phẩm thường xuyên thay đổi nên thẻ noarchive sẽ giúp người tìm kiếm luôn thấy giá mới nhất.
Ranking: Tìm hiểu về cách công cụ tìm kiếm xếp hạng trang web của bạn
Sau quá trình thu thập dữ liệu và lập chỉ mục, các công cụ tìm kiếm cần tạo bảng xếp hạng cho các kết quả có cùng liên quan tới một truy vấn nhất định. Quá trình này được gọi là xếp hạng trang web.
Các công cụ tìm kiếm sử dụng các thuật toán hiện đại để có thể cung cấp các thông tin có ý nghĩa cho người dùng khi tìm kiếm. Các thuật toán này được thay đổi từng ngày, nhằm mục đích cải thiện chất lượng kết quả xếp hạng mang đến những nội dung tốt nhất cho từng truy vấn của người tìm kiếm.
Khi bạn tối ưu và phát triển website, bạn cần chắc chắn rằng mình đang tuân thủ nguyên tắc chất lượng của Google và nguyên tắc đánh giá chất lượng tìm kiếm.
Tầm quan trọng của các liên kết trong SEO
Internal link và Backlink là 2 loại liên kết được nhắc tới mỗi khi ta nói về liên kết. Internal link là những liên kết nội bộ bên trong website của bạn, trong khi Backlink là những liên kết từ các trang khác trỏ tới trang web của bạn.
Từ những ngày sơ khai của công cụ tìm kiếm thì liên kết đã đóng một vai trò rất quan trọng trong SEO. Các liên kết giúp Googlebot xác định được URL nào là quan trọng hơn so với các URL trong trang web, và từ đó Google có thể xếp hạng kết quả tìm kiếm được tốt hơn.
Các backlink (liên kết ngược) giống như phiếu bầu để giúp website của bạn lên TOP. Càng nhiều liên kết về lý thuyết sẽ giúp website của bạn sẽ có thứ hạng cao hơn. Tuy nhiên bạn cần phân biệt mức độ ưu tiên của các loại liên kết này. Trường hợp bạn nhận được các liên kết từ trang web uy tín thì rất tốt, nhưng nếu bạn nhận liên kết từ những trang kém uy tín thì rất có thể bạn sẽ bị gắn cờ spam.
Đó là lý do vì sao PageRank được tạo ra, PageRank là một thuật toán được đặt theo tên của những người sáng lập Google. Thuật toán này tính toán tầm quan trọng của các trang web bằng cách đo lường chất lượng và số lượng của các liên kết trỏ đến nó.
Như đã nói ở trên, về lý thuyết bạn càng có nhiều liên kết ngược tự nhiên từ các trang web có độ uy tín cao thì tỷ lệ website bạn có thứ hạng cao trên kết quả tìm kiếm càng cao.
Tầm quan trọng của nội dung trong SEO
Tất cả những gì công cụ tìm kiếm làm đều tập trung vào việc sắp xếp lại thông tin trên internet và mang đến cho người tìm kiếm câu trả lời tốt nhất. Và tất nhiên câu trả lời tốt nhất chính là nội dung của trang web. Nội dung ở đây có thể là bài viết dạng văn bản, có thể là video, cũng có thể là hình ảnh.
Một nội dung đáp ứng được ý định tìm kiếm của người tìm kiếm sẽ được coi là một nội dung chất lượng. Và Google sử dụng một chương trình máy tính để hỗ trợ việc xử lý thông tin và sắp xếp kết quả tìm kiếm phù hợp nhất. Chương trình này có tên gọi là RankBrain.
Tầm quan trọng của các chỉ số tương tác trong SEO
Google sử dụng rất nhiều các tín hiệu xếp hạng khác nhau, tuy nhiên với chúng tôi các chỉ số tương tác được cho là những chỉ số mang lại hiệu quả xếp hạng rõ rệt nhất. Một số điều sau đây có thể giúp bạn cải thiện thứ hạng rất tốt như:
- Tỉ lệ nhấp chuột từ Google (Càng nhiều người click vào website của bạn từ Google thì thứ hạng càng cao)
- Thời gian trên trang (time onsite) thời gian người dùng ở trên trang của bạn cũng góp phần thể hiện chất lượng nội dung trên website của bạn.
- Tỷ lệ thoát (tỷ lệ phần trăm của tất cả các phiên trang web mà người dùng chỉ xem một trang)
- Pogo-stick (người dùng nhấp vào một kết quả trên Google và sau đó quay lại SERP để chọn một kết quả khác)
Video giải thích về cơ chế tìm kiếm của Google
Video giải thích ngắn gọn về cơ chế tìm kiếm của Google do tôi thực hiện năm 2013